本文已收录在合集Apche Flink原理与实践中.
HBase作为谷歌BigTable的开源实现, 是构建在HDFS上的分布式键值数据库. 由于具有极高的读写性能, HBase已经在实时计算领域得到了广泛运用. 随着Flink在实时计算领域的普及, Flink与HBase的结合应用也是趋势使然. 从Flink 1.9开始就在SQL API层面增加了对HBase Connector的支持.
本文通过一个实际的应用案例对Flink SQL与HBase的结合应用进行实践, 整个过程只需要在SQL Client中编写SQL语句, 不需要写任何Java或Scala代码. 本文案例主要包含两种场景.
- 场景一是将Flink SQL的计算结果实时写入HBase;
- 场景二是在Flink SQL中利用HBase table进行Lookup Join.
本文的实践案例需要依赖Kafka SQL Connecter和HBase SQL Connecter, 将相关Jar包下载后置于$FLINK_HOME/lib目录下并重启Flink集群即可完成配置.
应用案例
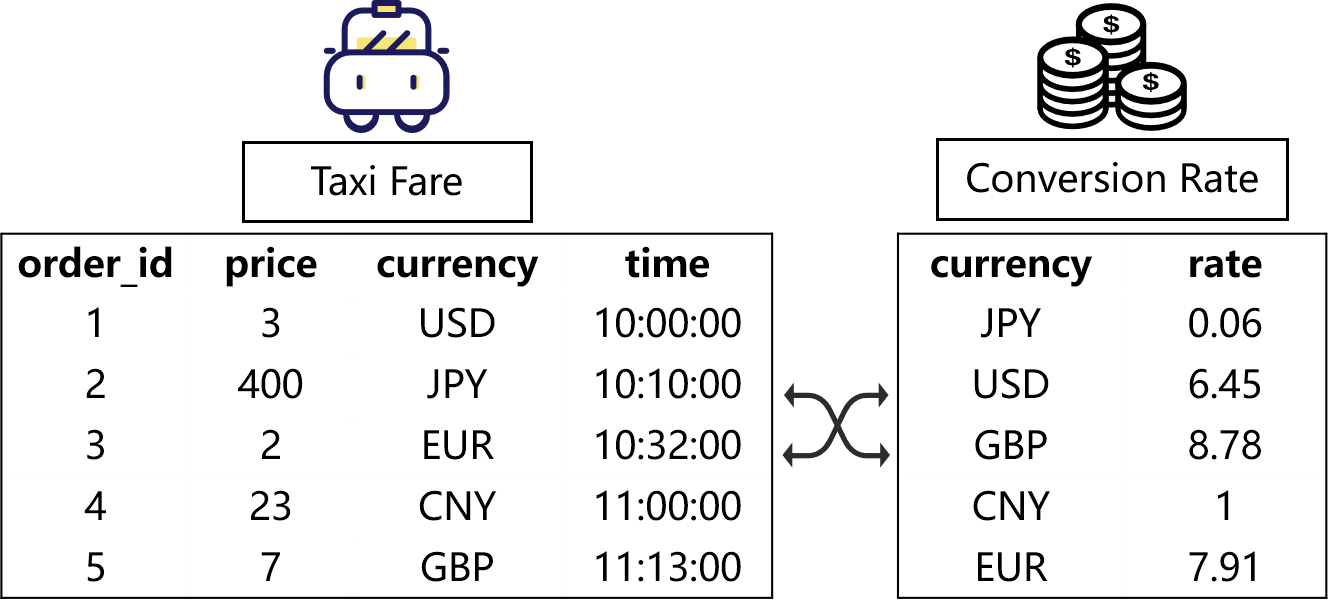
本文的案例考虑如下一种场景: 存在一种出租车订单信息流, 流中的每条记录都包含订单id(order_id), 订单金额(price), 交易货币(currency), 交易时间(time). 其中交易货币支持各种类型的货币, 比如美元(USD), 日元(JPY), 欧元(EUR), 英镑(GBP). 现在有两个需求:
- 实时计算每种货币的订单数量及订单总金额, 并写入数据库供前端业务进行实时展示;
- 给定一个汇率表, 记录了各种货币转换为人民币(CNY)的汇率, 通过关联该汇率表, 实时将每条记录成交金额转化为人民币.
这两个需求即分别对应文章开头所说的两种应用场景.
数据准备
出租车订单信息流
为方便复现本文案例, 在操作过程中我们并没有使用真实数据, 而是使用Python脚本生成模拟数据, 并通过Linux管道命令将数据写入Kafka. 由于Linux管道是批量刷写的, 所以进入Kafka的数据可能是按小批次写入的, 并不是逐条实时写入的.
通过如下命令创建Kafka topic orders, 如已经存在可先运行删除命令.
1 | # 删除orders topic |
生成出租车订单的Python脚本如下, 其文件名为txai_fare.py.
1 | import random |
运行如下命令即可通过Linux管道将taxi_fare.py脚本生成的模拟数据写入orders topic.
1 | python taxi_fare.py \ |
汇率表
汇率表存储在HBase中, 实际上是一个维表. 首先通过HBase shell创建HBase rates table. 创建命令如下.
1 | create 'rates', {NAME => 'f'} |
接着通过SQL Client创建Flink HBase table. 在控制台运行sql-client.sh embedded命令即可通过默认配置启动SQL Client. 建表语句如下.
1 | CREATE TABLE rates ( |
建表成功后通过如下语句写入几条示例数据用于实验.
1 | INSERT INTO rates |
为了验证写入是否成功, 可用过如下SELECT语句进行验证.
1 | SELECT * FROM rates; |
需要说明的是, 这里使用Flink SQL Client写入示例数据只是为了方便, 实际上汇率表的内容可能是由其它程序通过HBase客户端API写入的.
Flink SQL与HBase结合应用
场景一
HBase由于出色的写入性能, 常被用于实时大屏. 其构建流程如下图所示. 实时数据通常接入到Kafka, 然后由Flink对Kafka中的数据进行实时处理, 最终写入HBase供实时大屏进行展示.

上文提到的第一个需求其实就是一个实时大屏应用. 在数据准备阶段我们已经实现了不断生成出租车订单信息并写入Kafka, 这里我们就可以通过Flink SQL实时读取Kafka中的数据进行计算, 并将结果写入HBase. 下面我们具体讲述如何解决第一个需求.
在SQL Client中输入如下DDL创建Kafka orders表, 表示出租车订单信息流.
1 | CREATE TABLE orders ( |
在HBase shell中创建计算结果表order_agg, 用于存储每种金额成交的订单数量和订单总金额.
1 | create 'order_agg', {NAME => 'f'} |
在SQL Client中创建HBase order_agg table.
1 | CREATE TABLE order_agg ( |
通过如下语句执行计算, 并将结果写入HBase.
1 | INSERT INTO order_agg |
完成上述步骤后即可在HBase的order_agg表查询到实时的更新结果, 在实际应用中会通过前端界面展示实时计算的结果, 本文的重点不在于如何展示, 所以省略了这一步骤.
场景二
在流式数据的join中, 维度表的join一定是绕不开的. 为此, Flink SQL实现了Lookup Join. 而HBase作为分布式键值数据库, 相对于MySQL等关系型数据库有更好的并发性能和查询效率, 因此将维表存储在HBase中是更加合适的.
下面我们将通过Lookup Join解决上文提到的第二个需求. Flink Kafka table orders和Flink HBase table rates在上文中已经创建, 创建方式不再赘述.
在场景二中进行Lookup Join的目的是为orders表中的每条订单记录关联其对应货币的汇率并将交易金额转化为标准的人命币金额. 可通过如下DQL语句实现.
1 | SELECT |
上述DQL语句只是将结果在SQL Client中进行展示, 在实际应用中可能需要将相关记录写入HBase, 对此读者可以参考场景一的例子创建相应的表, 并将结果写入HBase. 本文对此不在赘述.
参考
[1] [技术生态篇]最佳实践: Flink流式导入HBase
[2] Flux capacitor, huh? Temporal Tables and Joins in Streaming SQL
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送