本文已收录在合集Apche Calcite原理与实践中.
Apache Calcite是一个动态的数据管理框架, 它可以实现SQL的解析, 验证, 优化和执行. 称之为”动态”是因为Calcite是模块化和插件式的, 上述任何一个步骤在Calcite中都对应着一个相对独立的模块. 用户可以选择使用其中的一个或多个模块, 也可以对任意模块进行定制化的扩展. 正是这种灵活性使得Calcite可以在现有的存储或计算系统上方便地构建SQL访问层, 甚至在已有SQL能力的系统中也可引入Calcite中的某个模块实现相应的功能, 比如Apche Hive就仅使用了Calcite进行优化, 但却有自己的SQL解析器. Calcite的这种特性使其在大数据系统中得到了广泛的运用, 比如Apache Flink, Apache Drill等都大量使用了Calcite, 因此理解Calcite的原理已经成为理解大数据系统中SQL访问层实现原理的必备条件.
笔者在学习Calcite的过程中发现关于Calcite的实践案例十分稀缺, Calcite文档中对于原理和使用方法的介绍也比较笼统, 因此准备对Calcite的相关内容进行总结整理, 由于整体内容较多, 后续计划每个模块安排一到两篇文章进行详细介绍. 本文是这一系列的第一篇, 重点介绍Calcite的架构, 并用一个可运行的例子来一步步分析Calcite在SQL解析, 验证, 优化和执行各个阶段所做的工作和输出的结果, 以形成对Calcite的整体了解. 关于Calcite的历史背景, 可以阅读参考[1], 本文不再赘述.
Calcite整体架构
Calcite的整体架构如下图(图片来自Calcite论文)所示, 它包含以下组成部分:
- JDBC接口: 用于使用标准的JDBC接口访问Calcite获取数据, 为了提供JDBC/ODBC接口, Calcite构建了一个独立的Avatica框架.
- SQL Parser和SQL Validator: 用于进行SQL的解析和验证, 将原始的SQL字符串解析并转化为内部的
SqlNode树表示. - Query Optimizer: 用于进行查询优化, 查询优化是在关系代数的基础上进行的, 在Calcite内部有一种关系代数表示方法, 即将关系代数表示为
RelNode树.RelNode树既可由SqlNode树转化而来, 也可通过Calcite提供的Expressions Builder接口构建. - Enumerator执行计划: Calcite提供了一种将优化后的
RelNode树生成为Enumerator执行计划的方法, Enumerator执行计划基于Linq4j实现, 这部分并未在图中画出. 由于多数系统有自己的执行接口, 因此Calcite的这部分组件在成熟的系统中较少使用. Calcite的一些Adapter使用了Enumerator执行计划.
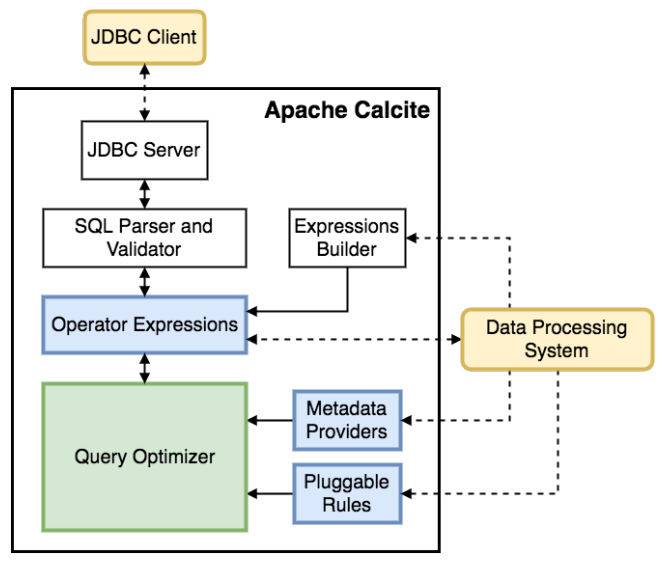
由上述架构可以看出, Calcite包含许多组成典型数据库管理系统的部件. 不过, 它省略了一些关键的组成部分, 例如, 数据的存储, 处理数据的算法和存储元数据的存储库. 这些省略是有意为之的, 因为在大数据时代, 对不同的数据类型有不同的存储和计算引擎, 想要将它们统一到一个框架中是不太可能的. Calcite的目的是仅提供构建SQL访问的框架, 这也是其广泛适用的原因. 这种省略带来的另一个好处是, 使用Calcite可以十分方便地构建联邦查询引擎, 即屏蔽底层物理存储和计算引擎, 使用一个统一的SQL接口实现数据访问.
Calcite处理流程
Calcite的完整处理流程实际上就是SQL的解析, 优化与执行流程, 具体步骤如下图所示.

从图中可以看出, Calcite的处理流程主要分为5个阶段:
- Parser用于解析SQL, 将输入的SQL字符串转化为抽象语法树(AST), Calcite中用
SqlNode树表示. - Validator根据元数据信息对
SqlNode树进行验证, 其输出仍是SqlNode树. - Converter将
SqlNode树转化为关系代数, 以方便进一步优化, Calcite中使用RelNode树表示关系代数. - Optimizer对输入的关系代数进行优化, 输出优化后的
RelNode树. - Execute阶段会根据优化后的
RelNode生成执行计划, 在Calcite中内置了一种基于Enumerator的执行计划生成方法.
为了更加深入地理解上述步骤, 笔者设计了一个小而全的案例, 通过Calcite实现使用SQL访问CSV文件. 后文我们将依据Calcite处理的5个阶段, 逐步分析每个阶段所做的工作和输出结果. 为方便阅读本文只给出了核心代码, 完整的可执行代码可参考这里.
如果读者阅读过Calcite的文档或源代码, 可能会发现Calcite已经包含了一个CSV Adapter, 可以实现CSV文件的访问. 不过Adapter需要借助JDBC接口使用, 而JDBC的调用链十分复杂, 不利于我们理解Calcite的核心处理步骤. 因此这里绕过了JDBC, 使用了一个更简易的案例. 通过本案例也可帮助理解Calcite Adapter的实现原理.
案例数据及SQL
在本文的案例中, 我们使用了两张表. 其中users表存储用户数据, orders表存储订单数据.
users表的内容如下.
1 | id:string,name:string,age:int |
orders表的内容如下.
1 | id:string,user_id:string,goods:string,price:double |
后文将基于上述两张表, 逐步分析以下SQL语句的解析和执行流程, 这一SQL语句用于查询每个用户的订单消费总额, 并按用户id排序后输出.
1 | SELECT u.id, name, age, sum(price) |
SQL解析
SQL语句处理的第一步便是通过词法分析和语法分析将SQL字符串转化为AST. 在Calcite中, 借助JavaCC实现了SQL的解析, 并转化为SqlNode表示. JavaCC是一种解析器生成器工具, 可以根据用户提供的语法规则文件自动生成解析器, 如果对如何使用JavaCC生成抽象语法树感兴趣可阅读笔者之前的博文编译原理实践 - JavaCC解析表达式并生成抽象语法树.
在Calcite中, SqlNode是AST节点的抽象基类, 不同类型的节点有对应的实现类. 比如上述SQL语句便会生成SqlSelect和SqlOrderBy两个主要的节点. 在Calcite中, 我们可以简单地使用如下代码将SQL字符串转化为SqlNode.
1 | String sql = "SELECT u.id, name, age, sum(price) " + |
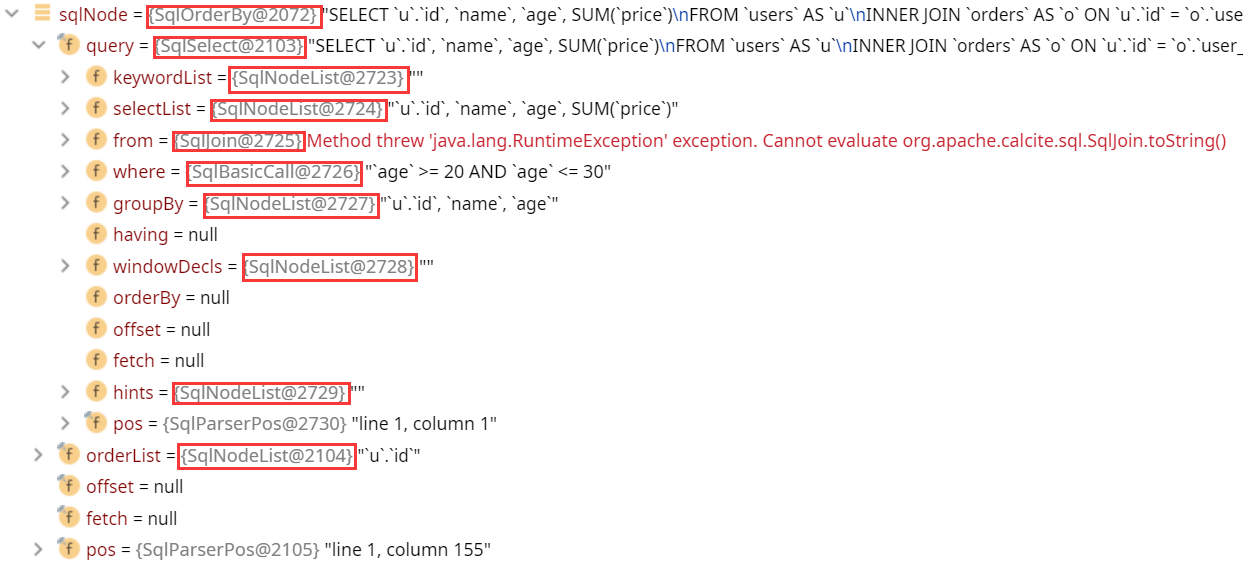
上述代码中的sqlNode是AST的根节点, 下图是将其展开后的结果. 可以看到sqlNode其实是SqlOrderBy类型, 它的query字段是一个SqlSelect类型, 即代表原始的SQL语句去掉ORDER BY部分. 图中红色矩形框内的其实都是SqlNode类型.
SQL验证
SQL解析阶段只是简单地将SQL字符串转化为SqlNode树, 并没有对SQL语句进行语义上的检查, 比如SQL中指定的表是否存在于数据库中, 字段是否存在于表中等. Calcite中的SQL验证阶段一方面会借助元数据信息执行上述验证, 另一方面会对SqlNode树进行一些改写, 以转化为统一的格式, 方便下一步处理.
在Calcite中可通过以下代码进行SQL验证.
1 | // 创建Schema, 一个Schema中包含多个表. Calcite中的Schema类似于RDBMS中的Database |
从上述代码中可以看到, SQL验证后的输出结果仍是SqlNode树, 不过其内部结构发生了改变. 一个明显的变化是验证后的SqlOrderBy节点被改写为了SqlSelect节点, 并在其orderBy变量中记录了排序字段.

另外, 如果把验证前后的SqlNode完全打印出来, 我们可以发现Calcite在验证时会为每个字段加上表名限定, 为每个表加上Schema限定. 读者可以试着故意把表名或者字段写错, 运行时在这一阶段就会报错.
1 | -- 验证前的SqlNode树打印结果 |
转化为关系代数
关系代数是SQL背后的理论基础, 如果读者不了解关系代数可阅读Introduction of Relational Algebra in DBMS作简单了解, “数据库系统概念“中对关系代数有更深入的介绍.
在Calcite中, 关系代数由RelNode表示, 我们可以通过以下代码, 将验证后的SqlNode树转化为RelNode树. 可以看到创建SqlToRelConverter的代码其实设计的并不十分优雅, VolcanoPlanner其实是在优化阶段使用的, 但是在转化为关系代数的时候就必须创建一个Planner, 这也是Calcite在抽象上有待提升的地方.
1 | // 创建VolcanoPlanner, VolcanoPlanner在后面的优化中还需要用到 |
RelNode树其实可以理解为一个逻辑执行计划, 上述SQL对应的逻辑执行计划如下, 其中每一行都表示一个节点, 是RelNode的实现类, 缩进表示父子关系.
1 | LogicalSort(sort0=[$0], dir0=[ASC]) |
查询优化
查询优化是Calcite的核心模块, 它主要有三部分组成:
- Planner rules: 即优化规则, Calcite已经内置了很多优化规则, 如谓词下推, 投影下推等. 用户也可定义自己的优化规则.
- Metadata providers: 这里的元数据主要用于基于成本的优化(Cost-based Optimize, CBO)中, 包括表的行数, 表的大小, 给定列的值是否唯一等信息.
- Planner engines: Calcite提供了两种优化器实现,
HepPlanner用于实现基于规则的优化(Rule-based Optimize, RBO),VolcanoPlanner用于实现基于成本的优化.
本文中暂且只使用VolcanoPlanner, 执行优化的代码如下. EnumerableRules中的规则用于将逻辑计划中的节点转化为对应的EnumerableRel节点, 它是Calcite中提供的物理节点, 可用于生成执行代码.
1 | // 优化规则 |
经过优化后的输出如下, 可以看到所有的节点都变成了Enumerable开头的物理节点, 它们的基类是EnumerableRel.
1 | EnumerableSort(sort0=[$0], dir0=[ASC]) |
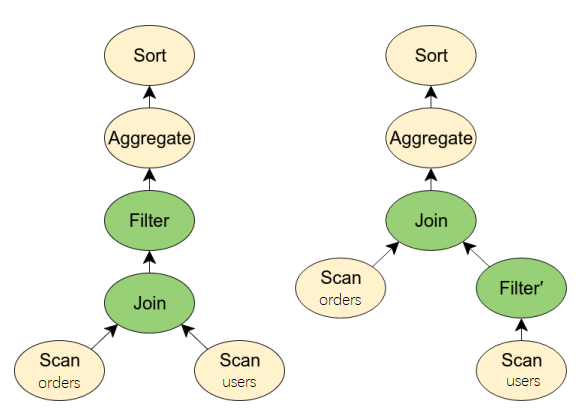
对比优化前后的计划, 另一个值得注意的变化是对users表的过滤位置发生了变动, 从先Join后过滤变成了先过滤后Join, 如下图所示.
生成执行计划
一般的存储或计算系统都有自己的执行计划, 因此为了将物理计划转化为执行计划通常需要用户编写代码. 不过Calcite中也提供了一种执行计划生成方法, 为了完整性我们这里使用它来生成访问CSV文件的执行计划. 通过如下代码即可生成执行计划并读取CSV文件中的数据.
1 | EnumerableRel enumerable = (EnumerableRel) optimizerRelTree; |
执行上述代码后可以看到如下结果.
1 | 1,Jack,28,42.40 |
至此, 我们成功地借助Calcite实现了使用SQL查询CSV文件中的数据, 其核心代码也就200行左右.
总结
本文通过一个小而全的案例囫囵地过了一遍Calcite的整个处理流程, 希望能借此构建对Calcite的整体理解. 具体到各个模块, Calcite其实还有很多细节和概念, 笔者计划在后续的文章中再深入讲解. 通过本文的案例也可以看到, 借助Calcite可以十分方便地构建SQL访问层. 不过Calcite最强大的还是在于其可扩展性, 本文所述的每个步骤都可以进行自定义的扩展, 这也使其在业界得到了广泛的运用, 比如Apache Flink的SQL API就重度依赖Calcite, 相信未来更多的大数据系统在构建SQL访问层时都会优先考虑Calcite.
参考
[1] Apache Calcite: Hadoop中新型大数据查询引擎
[2] SQL over anything with an Optiq Adapter
[3] Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
[4] Apache Calcite 处理流程详解(一)
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送