本文已收录在合集Apche Calcite原理与实践中.
本文是Apache Calcite原理与实践系列的第二篇, 将会详细介绍Calcite的SQL解析器的实现原理. 最后讲述如何通过扩展Calcite的SQL解析器来实现自定义SQL语法的解析, 比如解析Flink中的CREATE TABLE (…) WITH (…)语法等.
如果读者对Calcite不甚了解, 建议先阅读本系列的第一篇文章, 可以对Calcite的功能和处理流程有一个整体的把握.
Calcite SQL解析
SQL解析器构建
在第一篇文章中已经说到, Calcite的处理流程类似于编译器的处理流程, 第一步就是对SQL字符串进行词法和语法分析, 将其转化为AST. 在现代化的编译器构建中, 一般会借助解析器生成器工具(如Yacc, Anltr, JavaCC等)来自动生成解析器实现词法和语法分析并构建AST. Calcite的SQL解析器同样是基于JavaCC实现的, 要使用JavaCC生成SQL解析器就要提供一个描述SQL词法和语法的Parser.jj文件. 我们当然可以手动编写该文件, 不过Calcite为了方便用户对SQL解析器进行扩展, 使用了FMPP来生成Parser.jj. 这样用就只需要在相关的配置文件中更改或添加新的SQL语法, FMPP就会为我们生成相应的Parser.jj文件, 而无需在扩展时复制整个Parser.jj再进行更改. Calcite解析器的生成流程如下图所示.
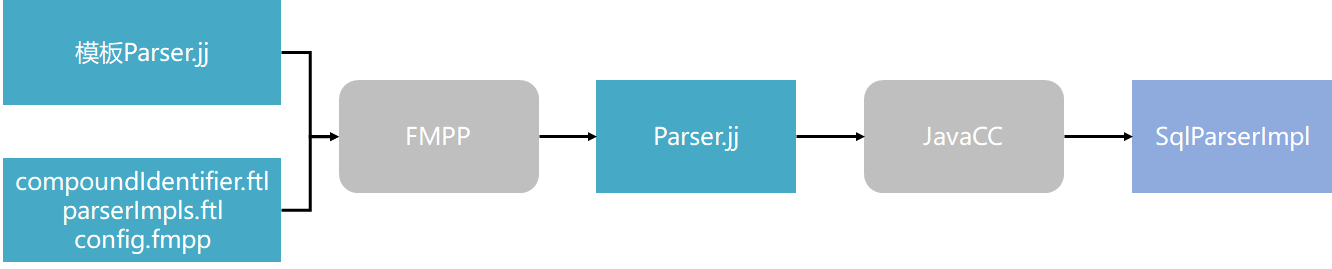
对上述流程的具体说明如下:
compoundIdentifier.ftl与parserImpls.ftl是扩展文件, 里面可以添加自定义的SQL语法规则,config.fmpp是FMPP的配置文件, 指定需要包含哪些扩展文件.- 模板
Parser.jj是一个模板文件, 里面引用了compoundIdentifier.ftl与parserImpls.ftl中的内容, 注意模板Parser.jj并不能直接输入JavaCC. - 上述文件输入FMPP后, 会组合生成一个可用的
Parser.jj文件, 这就是Calcite的SQL解析器语法规则文件, 里面包含预定义的SQL语法规则, 也包含用户新增的规则. Parser.jj文件输入JavaCC后就会生成一个继承自SqlAbstractParserImpl的SqlParserImpl类, 它就是Calcite中真正负责解析SQL语句并生成SqlNode树的类. 当然解析器的类名是可以自定义的.
上述文件都可以在Calcite core模块的codegen文件夹下找到. 以下是其目录结构, 其中default_config.fmpp是一个默认的config.fmpp文件, 可以仿照其中的格式新增相关内容. 关于这些文件的具体内容在后文SQL语法扩展部分还会进一步讲解, 现在只需要知道这些文件都是用来生成Parser.jj文件的, 之所以要使用FMPP是为了方便用户扩展.
1 | codegen |
SQL解析树相关概念
在Calcite中, 把SQL解析后的结果称为解析树(Parse tree), 实际上就是我们之前说过的SqlNode树. SqlNode是解析树中节点的抽象基类, 不同类型的节点有不同的实现类. 为了更好地理解解析树的结构, 这里先介绍一下SqlNode的相关实现.
SqlNode子类如下图所示.

1 | CREATE TABLE t ( |
为了有更直观的感受, 我们配合以上SQL语句来讲解SqlNode各个子类所代表的含义.
SqlIdentifier代表标识符, 上述SELECT语句中ca,cb,cc以及t在解析树中都是一个SqlIdentifier实例.SqlLiteral代表常量, 上述SELECT语句中10在解析树中就是一个SqlLiteral实例, 它的具体实现类是SqlNumericLiteral, 表示数字常量.SqlNodeList表示SqlNode列表, 上述SELECT语句中ca,cb,cc会共同组成一个SqlNodeList实例.SqlCall是对SqlOperator的调用. (SqlOperator可以用来描述任何语法结构, 所以实际上SQL解析树中的每个非叶节点都是某种SqlCall). 上述整个SELECT语句就是一个SqlCall实例, 它的具体实现类是SqlSelect.SqlDataTypeSpec表示解析树中的SQL数据类型, 上述CREATE语句中的INT,DOUBLE,VARCHAR在解析树中都是一个SqlDataTypeSpec实例.SqlIntervalQualifier代表时间间隔限定符, 比如SQL中的INTERVAL '1:23:45.678' HOUR TO SECOND在解析树中就是一个SqlIntervalQualifier实例.SqlDynamicParam表示SQL语句中的动态参数标记.
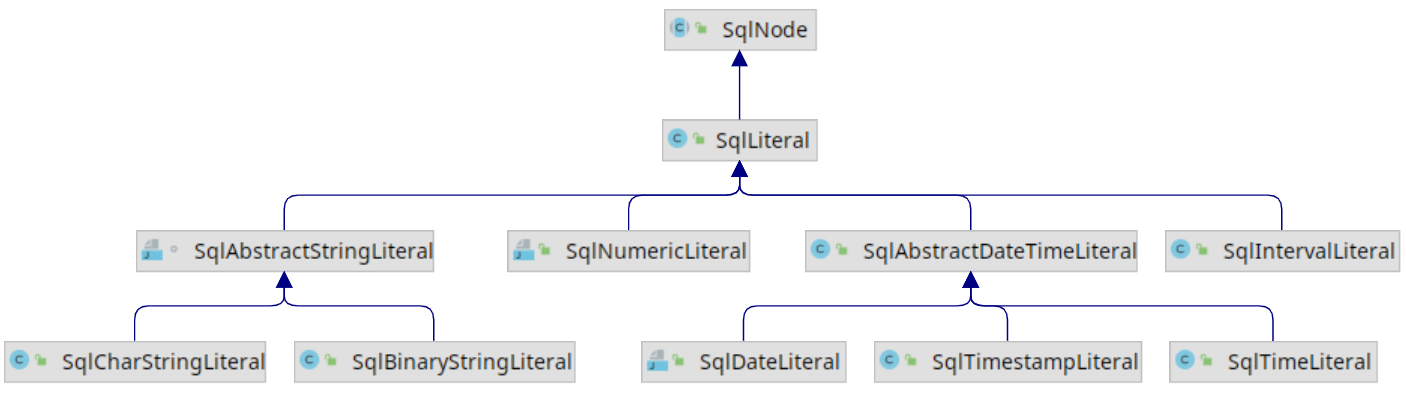
在SqlNode的子类中, SqlLiteral和SqlCall有各自的实现类. 我们先分析简单的SqlLiteral及其实现类, 它的类继承结构如下图所示. 其实每种实现类就代表了一种特定的常量类型, 比如字符串, 数字, 时间, 时间间隔. 根据类名即可望文生义, 这里不再过多介绍.
由于SqlCall的实现类较多, 这里我们仅选择部分有代表性的实现类进行详细介绍.
SqlSelect表示整个SELECT语句的解析结果, 内部有from,where,group by等成员变量保存对应字句内的解析结果.SqlOrderBy表示带有ORDER BY的SELECT语句的解析结果.SqlInsert和SqlDelete分别代表INSERT和DELETE语句的解析结果.SqlJoin表示JOIN子句的解析结果.SqlBasicCall表示一个基本的计算单元, 持有操作符和操作数, 如WHERE子句中的一个谓词表达式就会被解析为SqlBasicCall.SqlDdl是DDL语句解析结果的基类. 以CREATE TABLE语句为例, 它就会被解析成SqlCreateTable实例.

上文说到SqlCall其实是对SqlOperator的调用, 因此我们有必要进一步看一下SqlOperator的实现. SqlOperator其实可以表达SQL语句中的任意运算, 它包括函数, 操作符(如=)和语法结构(如case语句). SqlOperator可以表示查询级表达式(如SqlSelectOperator或行级表达式(如SqlBinaryOperator). 由于SqlOperator的实现类较多, 这里我们同样仅挑选几个有代表性的类进行说明.
SqlFunction表示SQL语句中的函数调用, 如SqlCastFunction表示cast函数, 在解析阶段所有自定义函数都会被表示为SqlUnresolvedFunction, 在验证阶段才会转化为对应的SqlUserDefinedFunction.SqlSelectOperator表示整个SELECT查询语句.SqlBinaryOperator表示二元运算, 如WHERE子句中的=运算.

SQL解析流程
有了上一节的介绍, 相信读者对SQL解析树的组成结构已经有了了解, 接下来我们再来讲述Calcite是如何解析SQL字符串, 并将其组成为解析树的.
在上一篇文章中我们是使用SqlParser作为入口来解析SQL语句的, 只不过当时我们使用了默认的配置, 实际上等同于以下代码.
1 | SqlParser.Config config = SqlParser.config() |
SqlParserImpl.FACTORY静态成员变量是定义在Paser.jj中的, 因此会生成到SqlParserImpl类中. 它的定义如下, 调用其getParser函数就会得到一个SqlParserImpl实例.
1 | public static final SqlParserImplFactory FACTORY = new SqlParserImplFactory() { |
SqlParserImpl.FACTORY在SqlParser.create中会被用到, SqlParser中的相关代码如下. 可以看到, SqlParser中实际包含了一个SqlParserImpl, 当我们调用SqlParser.parseStmt解析SQL语句时, 内部其实会调用SqlParserImpl.parseSqlStmtEof, 这个函数是定义在Parser.jj中的.
1 | public static SqlParser create(String sql, Config config) { |
现在我们终于来到Parser.jj中了, 由于SqlParserImpl是由Parser.jj自动生成的, 比较难阅读, 又因为两者间的函数其实是一一对应的, 所以我们这里主要分析Parser.jj中的代码. 只不过Parser.jj中的函数是用扩展的巴科斯范式(EBNF)以及JavaCC的action描述的, 如果对相关内容不熟悉建议先阅读笔者之前的博文编译原理实践 - JavaCC解析表达式并生成抽象语法树, 以快速了解Parser.jj的相关语法.
parseSqlStmtEof函数的调用链是比较长的, 其到SELECT语句解析的调用链如下. 这里我们只具体讲述调用链中的两个重要函数SqlStmt()和SqlSelect().
1 | parseSqlStmtEof() |
SqlStmt()的定义如下, 可以看到这是一个解析各类SQL语句的总入口, |表示或. 由于查询语句相对复杂, 会在OrderedQueryOrExpr实现.
1 | SqlNode SqlStmt() : // 会生成SqlParserImpl中的SqlStmt()函数 |
SELECT语句最终会通过SqlSelect()来解析, 其详细代码如下, 即使不了解JavaCC的EBNF语法, 只要了解正则表达式, 详细配合注释也能大致理解以下代码.
1 | SqlSelect SqlSelect() : |
Calcite的Parser.jj文件内容是比较多的, 默认实现下总共有八千多行, 不过也没有必要阅读所有的代码, 只要在需要时通过调用链路阅读关键代码即可.
Calcite SQL语法扩展
上文介绍了Calcite SQL解析器的实现原理, 并具体介绍了SELECT语句是如何解析的. 尽管Calcite已经提供了SQL语言的一个超集, 但是底层系统丰富多样, 实践中我们仍可能需要扩展一些自定义的SQL语法来支持特定功能. 比如Flink和Spark在使用SQL创建表时, 需要一些额外信息用于指定数据源的类型, 位置和格式. 本文以Flink的CREATE TABLE (…) WITH (…)语法为例, 介绍如何扩展Calcite的SQL解析器.
上文已经介绍过Calcite的解析器是如何构建的, 在扩展时我们也需要准备相应的文件. 一般来说, 我们会使用与Calcite类似的目录组织, 在codegen文件夹下放置相关的扩展文件, 目录结构如下所示. 这里的目录结构借鉴自Flink, 增加了Parser.tdd文件, 用于简化config.fmpp的编写. 这里我们不需要复制Calcite的模板Parser.jj文件, 因为该文件不需要修改, 在编译时可以从Calcite的JAR包中自动提取.
1 | codegen |
下面我们来具体介绍一下各个文件中的内容. config.fmpp文件中的内容如下, 通过引入Parser.tdd文件, 我们可以把data部分的内容转移到Parser.tdd中, 从而使config.fmpp文件更加简洁.
1 | data: { |
这里需要注意的一点是, Calcite的core模块并未提供DDL语法的解析, 这部分是在server模块中扩展的, 当我们需要扩展DDL语法时最简单的做法是将server模块中的实现先复制过来, 再进行更改. 操作步骤如下:
- 将Calcite server模块中parserImpls.ftl文件中的内容复制到我们自己的
parserImpls.ftl文件中. - 将Calcite server模块中config.fmpp文件中
data部分的内容复制到我们自己的Parser.tdd文件中.
经过上述操作之后, 其实我们就可以编译生成可以解析DDL的解析器了, 当然我们需要在pom.xml文件中引入一些插件并做一些配置, 来自动生成解析器, 详细配置可参考这里. 编译完成之后我们可以通过如下代码解析DDL, 注意这里使用的是SqlDdlParserImpl.FACTORY而不再是SqlParserImpl.FACTORY.
1 | SqlParser.Config config = SqlParser.config() |
经过上述准备, 我们已经可以在自己的工程中生成可以解析DDL语句的解析器了. 为了实现CREATE TABLE (...) WITH (...)语法, 我们只需要在现有基础上进行一些修改即可.
首先介绍Parser.tdd文件, 其主要内容如下, 这里面配置了生成的解析器类名, 以及需要引入的新的关键字以及语法规则等.
1 | { |
真正实现解析CREATE TABLE语句的是parserImpls.ftl中的SqlCreateTable方法, 编译时它会合并到Parser.jj文件中, 它的默认实现如下. 可以看到默认试下是不支持WITH选项的.
1 | SqlCreate SqlCreateTable(Span s, boolean replace) : |
为了支持WITH选项, 我们对SqlCreateTable方法做如下修改.
1 | SqlCreate SqlCreateTable(Span s, boolean replace) : |
在上述函数中, 我们引入了一个新的类SqlTableOption, 这个类是需要我们自己定义的. 另外由于引入了WITH语句, 我们也需要对SqlCreateTable进行修改, 在其中增加一个SqlNodeList类型的成员变量用于保存WITH语句中的键值对. 核心代码如下.
1 | public class SqlCreateTable extends SqlCreate { |
到这里为止, 我们就完成了CREATE TABLE (...) WITH (...)语法的扩展, 完整的代码在这里. 读者可以下载相关代码进行体验, mvn clean package编译整个项目后, 运行CalciteSQLParser即可. 在CalciteSQLParser中, 我们使用了扩展后的解析器, 主要传入的工厂类是CustomSqlParserImpl.FACTORY.
1 | String ddl = "CREATE TABLE aa (id INT) WITH ('connector' = 'file')"; |
总结
Calcite的解析器是基于JavaCC构建的, 要真正理解解析器的实现原理, JavaCC相关的知识肯定是越多越好. 如果熟悉类似的解析器生成工具如Antlr等, 相信可以很快掌握JavaCC的语法. SQL解析的过程其实就是编译器前端的工作, 都是为了生成AST, 只不过AST的结构有所区别, 如果对这方面不太了解的可以参考笔者之前的博文编译原理实践 - JavaCC解析表达式并生成抽象语法树, 以表达式为例, 讲述如何通过JavaCC将其解析为AST并计算.
Calcite的强大之处就在于其扩展性, 我们可以通过JavaCC的EBNF语法快速实现自定义语法的解析. 本文的案例给出了如何扩展SQL语法的模板, 读者可以依葫芦画瓢实现自己的SQL语法.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送