本文已收录在合集Apche Calcite原理与实践中.
本文是Apache Calcite原理与实践系列的第四篇, 前两篇文章介绍了SQL语句的解析及验证, 本文开始介绍关系代数的原理与实现. 关系代数最早由E. F. Codd在1970年的论文”A Relational Model of Data for Large Shared Data Banks“中提出, 是关系型数据库查询语言的基础, 也是查询优化技术的理论基础. 随着关系代数和关系模型的不断发展和完善, 目前几乎所有对外支持SQL访问的系统, 都会将SQL转化为等价的关系代数表达, 并基于此进行查询优化. 在Calcite内部, 同样会将SQL查询转化为一颗等价的关系算子树, 并在此基础上进行查询优化. 本文首先介绍通用的关系代数理论, 之后介绍其在Calciate中的实现.
关系代数
Codd提出的关系代数的6个原始运算是选择(Select), 投影(Project), 笛卡尔积(Cartesian-product), 并集(Union), 差集(Difference), 和重命名(Rename). 随着关系模型的不断发展, 更多的关系代数运算被提出, 目前主要的关系代数运算如下表所示.
| 类别 | 名称 | 符号 | 示例 |
|---|---|---|---|
| 一元运算 | 选择(Select) | $\sigma$ | 符号: $\sigma_{condition}(R)$ SQL: SELECT * FROM R WHERE condition |
| 投影(Project) | $\Pi$ | 符号: $\Pi_{x, y}(R)$ SQL: SELECT x, y FROM R |
|
| 赋值(Assignment) | $\gets$ | 符号: $$ t \gets \Pi_{x, y}(\sigma_{condition}(R)) $$ SQL: CREATE VIEW t AS SELECT x, y FROM R WHERE condition |
|
| 重命名(Rename) | $\rho$ | 符号: $\rho_{S(x1, y1)}(R)$ SQL: SELECT * FROM (SELECT x AS x1, y AS y1 FROM R) AS S |
|
| 二元运算 | 并(Union) | $\cup$ | 符号: $R \cup S$ SQL: SELECT * FROM R UNION SELECT * FROM S |
| 交(Intersection) | $\cap$ | 符号: $R \cap S = R - (R-S)$ SQL: SELECT * FROM R WHERE x NOT IN (SELECT x FROM R WHERE x NOT IN (SELECT x FROM S)) |
|
| 差(Difference) | $-$ | 符号: $R - S$ SQL: SELECT * FROM R WHERE x NOT IN (SELECT x FROM S) |
|
| 笛卡儿积(Cartesian-product) | $\times$ | 符号: $R \times S$ SQL: SELECT * FROM R, S |
|
| 除(Divide) | $\div$ | 符号: $R \div S$ SQL: SELECT DISTINCT r1.x FROM R AS r1 WHERE NOT EXISTS (SELECT S.y FROM S WHERE NOT EXISTS (SELECT * FROM R AS r2 WHERE r2.x = r1.x AND r2.y = S.y)) |
|
| 连接(Join) | $\Join$ | 符号: $R \Join_{condition} S$ SQL: SELECT * FROM R JOIN S ON condition |
注: 其中$R$和$S$表示关系, $x$, $y$和$z$表示关系中的属性或列.
上述运算中, 其中一部分仅在一个关系上进行运算, 一般称为一元运算. 另一部分在一对关系上进行运算, 称为二元运算. 其中二元运算中大多数都是集合运算(并, 交, 差, 笛卡尔积), 连接是一种比较特别的关系运算, 上表中的连接更准确地来说是自然连接. 随着关系模型的广泛使用, 越来越多的连接运算被提出和应用.
下图(图片来自C.L. Moffatt的博文)通过可视化的方式直观地展示了各类常见连接的含义及其对应的SQL表示方法.

SQL是一种基于关系代数的数据库查询语言, 目前已经成为了关系代数模型的标准接口, 它实现了绝大多数的关系运算, 但不是全部. 所有的SQL语句都可以转化为等价的关系代数表示.
从SQL到关系代数
类似于编译器会首先将高级语言转化为中间表示(IR), 然后对IR进行优化, 最后转化为目标机器语言. Calcite会先将SQL语句解析为SqlNode树(实际上是一种抽象语法树(AST)), 之后Calcite会将SqlNode树转化为RelNode树(即Calcite中的IR)并进行查询优化.
以下是一个将SQL解析为SqlNode树, 再转化为RelNode树的案例. 关于Calcite中SQL解析的内容已经在本系列的第二篇文章中介绍了, 本文接下来的部分将会介绍从SqlNode到RelNode的转换.
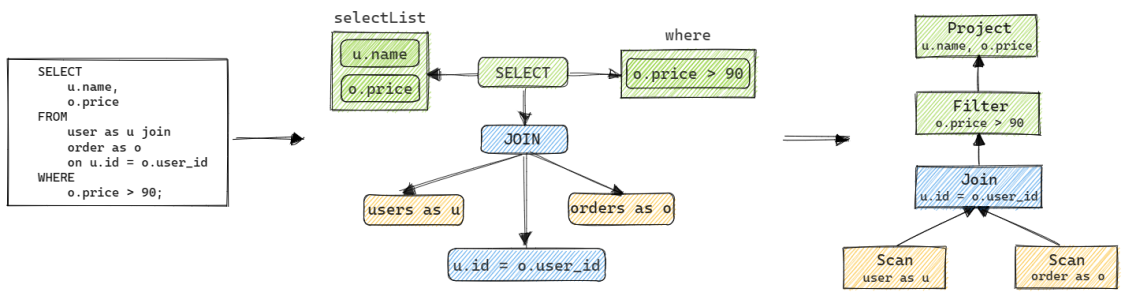
为了方便表述, 本文接下来将某个关系运算的具体实现, 即具体的RelNode实现类, 称为关系算子或简称为算子.
Calcite关系算子实现
Calcite的核心是查询优化, 其背后也是基于关系代数实现的. 接下来本文将详细介绍Calcite中关系算子的实现. 实现关系算子的最终目的是进行等价转换从而实现查询优化和执行计划生成, 因此本文会同时介绍Calcite关系算子中与查询优化和执行计划相关的概念.
RelNode
RelNode类型及继承关系
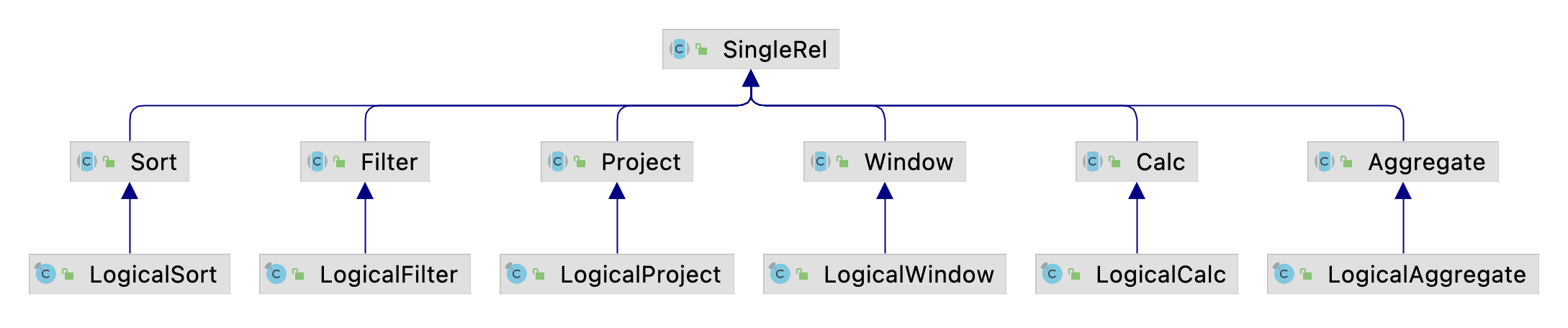
RelNode是Calcite中关系算子的父类型, 代表了对关系的一种处理操作. 所有的关系算子都是它的子类型, 它的几个上层子类型的继承关系如下图所示.

实际上关系算子的最顶层类型是
RelOptNode, 不过在Calcite的代码和文档中经常出现的是RelNode, 因此这里我们也用RelNode进行讲述.
我们常见的关系算子都是AbstractRelNode的子类型, 其中:
SingleRel是一元算子的父类型, 其子类型包含常见的Project,Filter,Aggregate等.
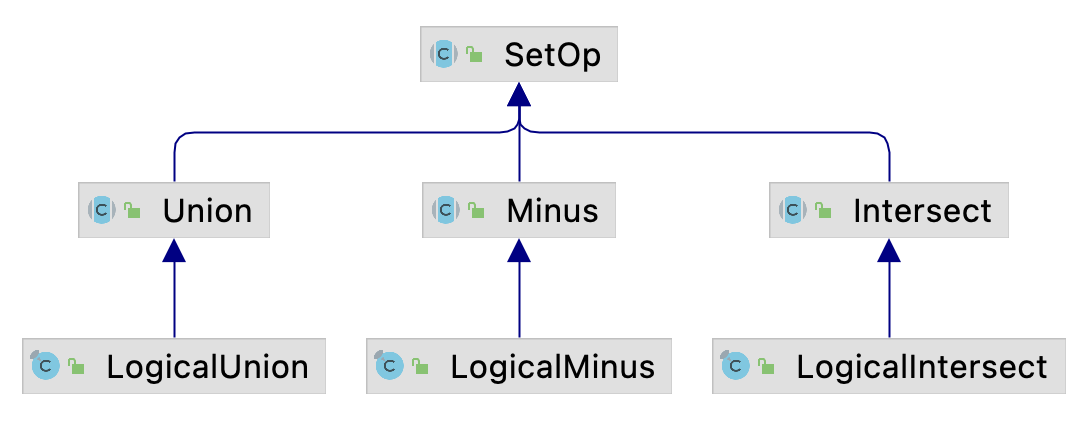
BiRel是Join算子的父类型.SetOp是集合算子的父类型, 其子类型包含Union,Intersect,Minus.
AbstractRelNode属于逻辑算子, 与物理执行无关. EnumerableRel和BindableRel是Calcite中的物理算子, 可以转化为执行计划, 从底层数据源中获取数据. 具体来说EnumerableRel是通过代码生成的方式来生成执行计划的, 而BindableRel是通过解释执行的. 关于Calcite的执行计划会在后续的文章中详细介绍.
Converter虽然也是RelNode的子类型, 但它实际上不代表一种关系运算, 而是不同RelNode之间的转换器. 通常来说是将逻辑算子转换为物理算子或执行计划, 在后续关于执行计划的文章中会进一步介绍Conveter.

RelNode的子类型很多, 为了方便表述和理解, 本文将其在横向和纵向两个维度进行分类. 横向上存在各种不同种类的关系算子, 例如Project, Filter等; 纵向上存在不同属性的关系算子, 例如Project既有LogicalProject也有EnumerableProject. 由于Calcite支持多种数据源, 对于每种数据源都会有多个相同属性不同种类的关系算子.

RelNode内部实现
介绍完RelNode的种类, 我们再来看下RelNode的具体实现. 以下是RelNode中几个比较重要的方法, 本文重点要介绍的是与物理属性有关的两个方法, 关于查询优化相关的方法会在后续关于查询优化器的文章中介绍.
getTraitSet()用于获取当前算子的所有物理属性集合, 可以看到在AbstractRelNode中包含一个RelTraitSet类型的属性, 它实现了AbstractList<RelTrait>用于保留所有物理属性;getConvention()用于获取当前算子的Calling Convertion(下文将详细介绍).
1 | public interface RelNode extends RelOptNode, Cloneable { |
RelTrait
RelTrait用于描述RelNode的物理属性, 它对于查询优化以及关系算子在逻辑和物理层面的转化都有重要影响. 举例来说, RelTrait可以用来描述RelNode的排序属性, 在查询优化时如果Sort算子的输入已经有序, 而且排序的目标列一致, 那么可以直接省略Sort算子以实现优化; 另外, RelTrait还可以用来描述RelNode的物理数据源, 这样就可将逻辑算子转换为指定的物理算子.
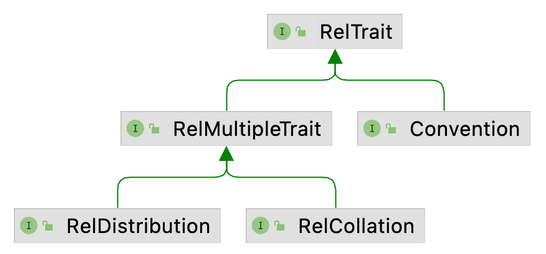
RelTrait的继承关系如上图所示, 它的3个子类型的主要含义如下:
RelCollation用于描述算子输出的排序属性.RelDistribution用于描述算子输出的分布属性, 如HASH_DISTRIBUTED,RANDOM_DISTRIBUTED等.Convention用于描述算子的底层数据处理引擎. 引入Convention可以让Calcite与底层的执行引擎解耦, 如果要适配新的执行引擎, 只需要扩展一个Convention实现即可, 如Flink中就有扩展的FlinkConvention. Calcite中已经实现的Convention如下图所示, 从名称中就可以看出是用于转换到什么执行引擎.
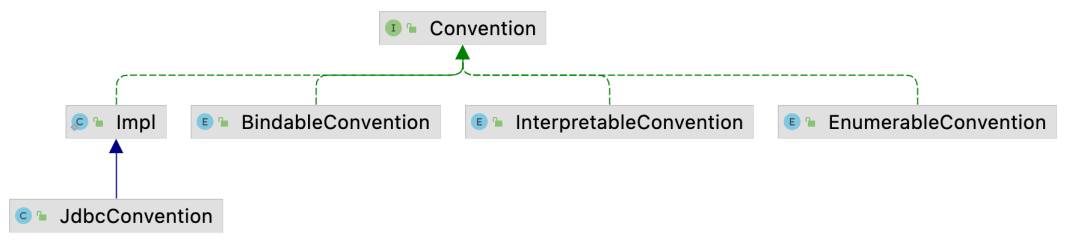
RelTraitDef
RelTraitDef代表一个RelTrait种类, 这里需要注意的是”种类”是指RelDistribution, RelCollation和Convention这三类, 而不是指具体的实现类. 也就是说JdbcConvention, EnumerableConvention以及其他Convention实现类的所对应的都是ConventionTraitDef, 在实现上它们的getTraitDef()方法都返回的是ConventionTraitDef.INSTANCE. RelTraitDef的实现类如下图所示.

Calling Convention
在RelNode相关的代码注释中经常会看到Calling Convention这个词, 从字面上理解它表示的是RelNode该如何被调用. 这个”调用”实际上应该理解为”转换”, 一般情况下是指从逻辑算子到物理算子的转换, 如从LogicalTableScan到EnumerableTableScan的转换.
从上文的介绍中也可以知道, 每个RelNode都会有一个RelTraitSet类型的变量来描述其当前的物理属性, 其中包含Convention. 对于逻辑算子, 其Convention一般是默认实现, 即Convention.Impl, 而物理算子则有其对应的Convention属性, 如EnumerableRel包含EnumerableConvention.
在Calcite中引入Calling Convention是为了方便对接多种不同的物理数据源, 不同属性间的算子转换由ConverterRule实现, 例如从LogicalTableScan到EnumerableTableScan的转换由EnumerableTableScanRule实现, 它是ConverterRule的一个实现, 顶层父类型是RelOptRule, 在后面关于查询优化器的文章中会有关于RelOptRule的详细介绍.
RexNode
RexNode表示一个行表达式. 如果说RelNode表示的是如何对一个关系或表进行操作, 那么RexNode表示的是如何对表中的一行进行操作. 其实现关系如下.
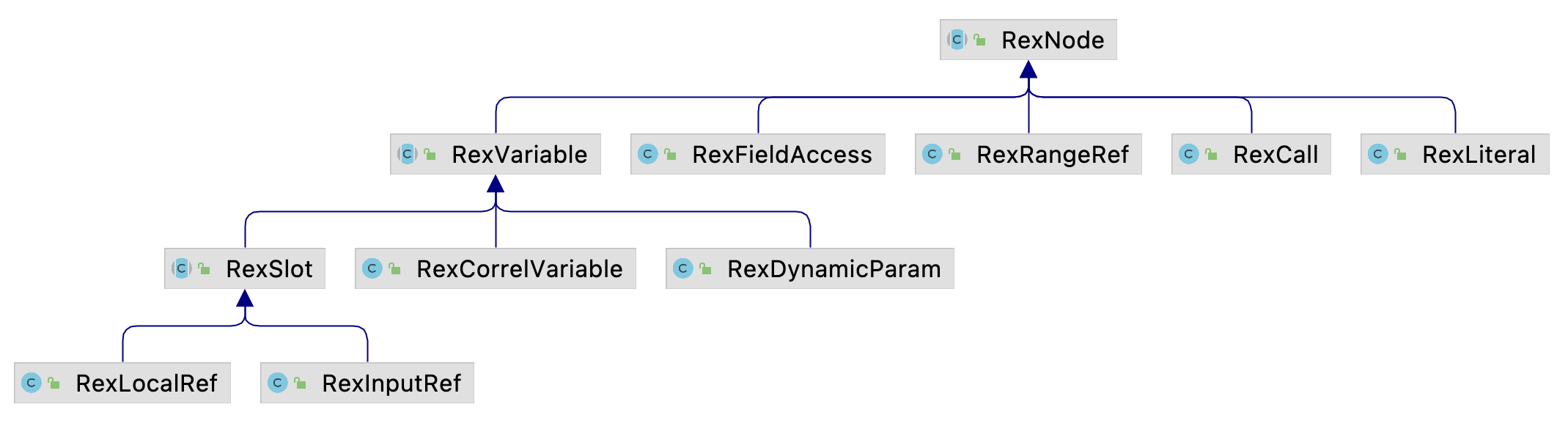
其中:
RexVariable代表变量, 一般是一个字段. 它的子类型中:RexDynamicParam代表SQL语句中的动态参数, 如SELECT name FROM users where id = ?中的?;RexLocalRef代表本地变量, 一般用于在一个节点内部相同字段相互之间的引用;RexInputRef代表字段引用, 用于上层节点对下层节点字段的引用;RexCorrelVariable代表一个字段, 用在Nested Loop Join中, 表示属于外表的关联字段. 比如SELECT u.name, o.price FROM user AS u JOIN order AS o on u.id = o.user_id中如果采用Nested Loop Join实现, 并且user为外表, 那么用RexCorrelVariable来表示u.id.
RexLiteral代表常量.RexCall代表表达式, SQL语句中的所有运算都是一个表达式, 如id = 1,id = 1 and name = 'Jack'.RexRangeRef代表多个列的集合.RexFieldAccess代表字段引用.
Calcite关系算子树构建
Calcite提供了SqlToRelConverter来实现从SqlNode到RelNode的转换, 实际上SqlToRelConverter的实现依赖于RelBuilder, 本节首先介绍如何基于RelBuilder构建关系算子, 之后分析SqlToRelConverter的实现原理.
RelBuilder
RelBuilder是Calcite中的关系算子生成器, 它提供的方法可用于快速生成绝大多数关系算子. 从整体上来看, RelBuilder所提供的方法可分为以下几类:
- 一类是生成
RelNode的方法, 如scan(),filter(),project()等. - 一类是生成
RexNode的方法, 如field(),and(),equals()等. - 还有其他一些辅助方法, 如生成
GROUP BY字段的groupKey()方法,
Calcite源代码中的RelBuilderExample包含了RelBuilder的详细示例, 本文不再赘述.
SqlToRelConverter
SqlToRelConverter用于将SqlValidator验证之后的SqlNode树转化为RelNode树, 其主要思想是通过遍历SqlNode树将其结点逐个转换为RelNode. 但是由于SqlNode种类众多, 其实现比较繁杂, 本文以一条简单的SQL语句为例, 来梳理从SqlNode到RelNode的整个转换流程.
我们以SELECT * FROM users;为例, 这条SQL语句的关系代数表示很容易通过肉眼看出, 在Calcite中的表示如下.
1 | LogicalProject(id=[$0], name=[$1], age=[$2]) |
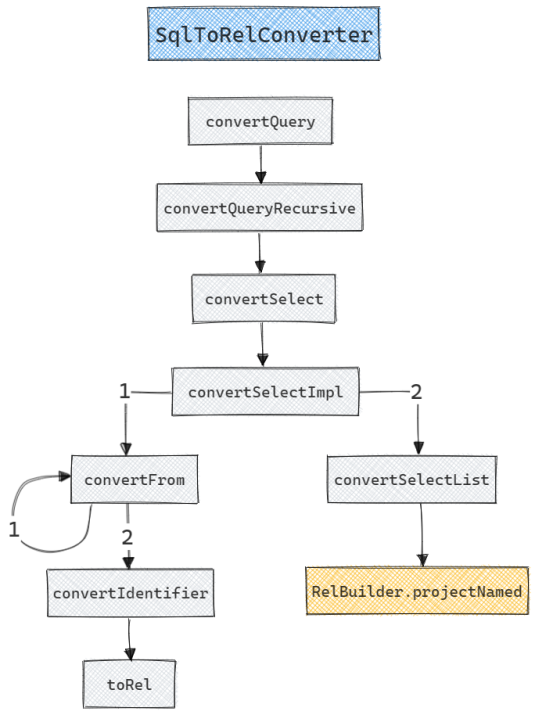
上述SQL语句的转换过程如下图所示:
convertQuery是SqlToRelConverter的入口, 它的输入是SQL语句对应的SqlNode表示;convertQueryRecursive会根据SqlNode的SqlKind来调用对应的方法进行转换, 如SELECT类型调用convertSelect,INSERT类型调用convertInsert等. 很明显上述示例SQL语句是SELECT类型, 因此会调用convertSelect;convertSelect做完简单的准备工作后会直接调用convertSelectImpl, 它会对SQL语句的各个部分分别进行转换, 如对SELECT字段调用convertSelectList, 对FROM子句调用convertFrom, 对WHERE子句调用convertWhere, 对GROUP BY子句调用convertAgg, 对ORDER BY子句调用convertOrder. 在本例中会首先调用convertFrom转换FROM子句, 然后调用convertSelectList转换SELECT字段;convertFrom会调用conevrtIdentifier将FROM users转换为LogicalTableScan;convertSelectList会将*展开为具体的字段名, 最后调用RelBuilder.projectNamed生成LogicalProject.
总结
关系代数是查询优化的基础, 本文介绍了Calcite中关系代数的实现. 可以看到, Calcite中关系算子的种类多样, 重点是要把握各个算子的抽象层次, 一般来说在扩展Calcite适配自定义数据源时, 只需实现对应的物理算子即可. Calcite提供了SqlToRelConverter来实现从SqlNode到RelNode的转换, 这一步得到的RelNode都是逻辑算子, 从逻辑算子到物理算子的转换将在RelOptPlanner中实现.
参考
[1] Apache Calcite Docs - Algebra
[2] Relational Operators in Apache Calcite
[3] Visual Representation of SQL Joins
附录
附录一: RelBuilder的创建
在RelBuilderExample中, RelBuilder是通过Frameworks创建的, 去除依赖之后的代码如下. Frameworks会自动创建RelBuilder所需的参数.
1 | SchemaPlus rootSchema = Frameworks.createRootSchema(true); |
为了更好地理解RelBuilder的创建过程, 笔者将Frameworks的创建过程拆解出来了, 以下代码同样可以创建RelBuilder. 从中可以看出, RelBuilder的创建需要两个参数:
RelOptCluster主要用于获取RexBuilder和RelDataTypeFactory, 这里笔者认为代码抽象得并不优雅, 实际上在构建RelNode的时候不需要用到RelOptPlanner.CatalogReader主要用于在创建TableScan时获取具体的表结构信息.
1 | CalciteSchema rootSchema = CalciteSchema.createRootSchema(false, false); |
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送