本文已收录在合集Apche Flink原理与实践中.
Flink SQL作为Stream SQL的事实标准, 已经得到了广泛的应用. 然而不同于Hive, Spark等离线引擎或数据库的SQL, 流式系统中的SQL有更多的隐藏特性和复杂度, 理解其内部实现是更好使用Flink SQL的基础. 为此, 笔者计划通过一系列文章对Flink SQL的执行框架进行抽茧剥丝, 详细介绍其内部实现. 本文是该系列的第一篇, 将从整体上介绍Flink SQL的执行流程. 后续文章会进一步介绍各个模块的具体实现.
Table API & SQL入口
在代码层面, TableEnvironment是使用Table API和SQL的统一入口, 其他Flink SQL的平台化能力, 如SQL Gateway等都是基于此构建的, 其使用方式如下.
1 | TableEnvironment tableEnv = TableEnvironment.create(/*…*/); |
由于Table API的使用场景较少, 在实现上跟SQL也有很大相似性, 因此本文及后续文章会将重点放在SQL的实现上. 此外, DDL语句的执行比较简单, 无非是元数据的操作, 重要的是DQL及DML语句的执行, 本文所介绍的执行流程也是指这两类SQL语句的执行.
整体执行流程
Flink SQL的解析及关系代数的优化都是通过扩展Apache Calcite实现的, 关于Calcite的原理解析在笔者之前的系列文章Apache Calcite原理与实践中已经详细介绍过, 这里将不再介绍过多的细节.
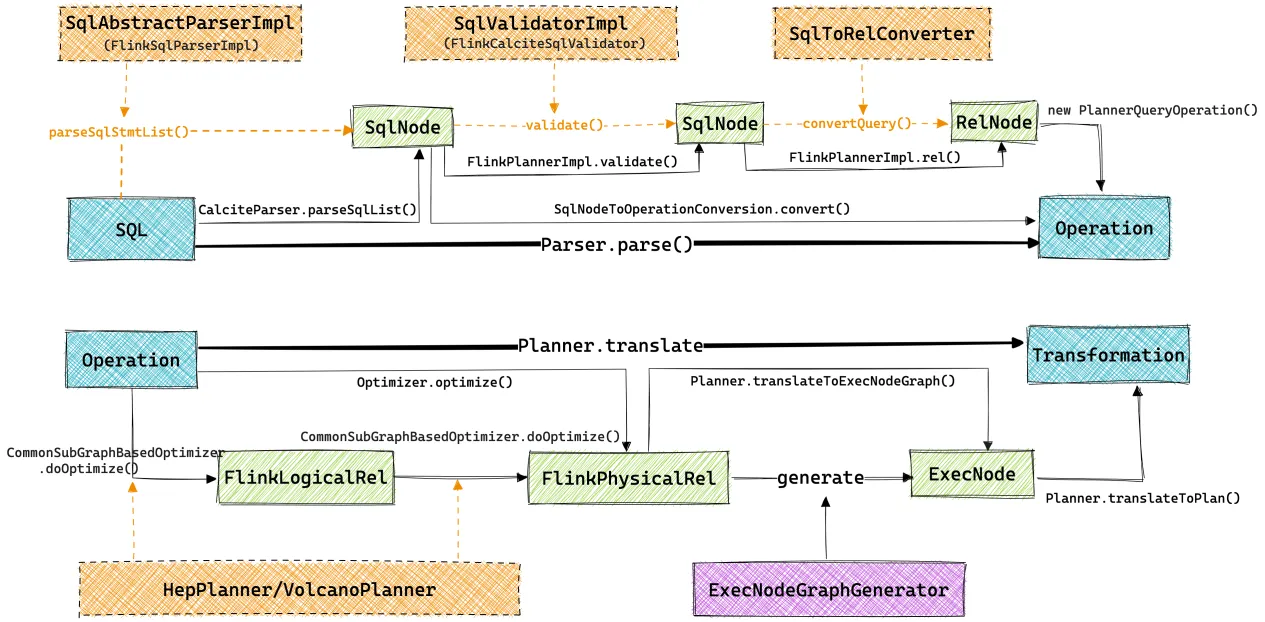
Flink SQL的整体执行流程如上图所示(其中黄色框中是Calcite中的核心模块, 包含Flink的扩展), 从端到端的视角来看, Flink SQL模块的任务就是将输入的SQL文本翻译为Flink的Transformation结构, 之后的提交和执行流程就跟DataStream作业一样了. 从SQL到Transformation的翻译过程都是在本地JVM中执行的, 这也给我们调试Flink SQL的执行过程带来了便利.
Operation是Flink引入的一种中间结构, 是Table API和SQL的统一中间表达. 以Operation结构作为分界, Flink SQL的执行过程可分为两个大的阶段, 即从SQL文本到Operation的转换以及从Operation到Transformation的转换.
从SQL文本到Operation的转换又可分为以下几个具体步骤:
- SQL解析: 将SQL文本解析为Calcite的
SqlNode结构, Flink在SQL语法上基于Calcite进行了一定扩展; - SQL验证: 将解析得到的
SqlNode配合元数据进行语义验证, 输出结构仍为SqlNode结构; - 关系代数转换: 将验证后的
SqlNode结构转换为RelNode结构, 即关系代数; Operation转换: 将RelNode结构封装为Operation, 具体就是封装为PlannerQueryOperation.
从Operation到Transform的转换又可分为以下几个步骤:
- DAG图预处理: Flink SQL可能包含多个INSERT语句, 因此生成的
RelNode会形成一个DAG结构, 而Calcite优化器不支持直接处理DAG. 因此Flink优化器会先对这个DAG进行一些预处理, 主要包括DAG子图复用, DAG子图分割; - 关系代数优化: DAG子图分割后的树结构就能输入Calicte优化器进行优化了, 主要是利用Calcite的HepPlanner和VolcanoPlanner进行关系代数优化, Flink在Calcite的基础上扩展了一系列优化规则和关系节点;
ExecNodeGraph生成: 将优化后的关系代数翻译成Flink定义的ExecNodeGraph结构. 它是SQL层最终的执行计划, 基于它可以进一步做DAG层的物理优化;Transformation生成: 将ExecNodeGraph进一步翻译为Transformation结构, 这一步会利用Codegen技术动态生成一些算子的Java代码.
源码模块
Flink Table API & SQL相关的实现都在flink-table模块下面, 其各个子模块的核心功能如下.
1 | flink-table # Table API & SQL实现父模块 |
总结
本文从宏观上介绍了Flink SQL的执行流程, 可以看到整个流程基本上是围绕Calcite框架展开的, 当然在其中也加入了一些Flink特有的步骤. Table Planner的核心目的就是通过分层优化, 将用户输入的SQL代码尽可能转化为Flink的底层执行计划(Transformation结构), 当然这当中涉及众多的优化细节, 将在后续的文章中逐步详细介绍.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送