本文已收录在合集Apche Flink原理与实践中.
本文是Flink SQL执行框架源码分析系列的第二篇, 将从整体上介绍与Table API和SQL实现相关的模块, 并解析内部是如何通过组合各个模块实现SQL的解析, 优化与执行的. 最后通过对现有模块的简单扩展来实现一个新的用户接口executeStatements, 该接口可直接运行用户提供的整个SQL脚本. 需要注意的是, 本文仅从宏观角度介绍Table API和SQL内部的各个模块是如何组合使用的, 具体实现原理会在后续的文章的详细介绍.
Table
Table是Table API的核心抽象, 它只有一个实现类TableImpl. Table仅是对如何获取和转换数据的描述, 并不持有数据. 作为类比, Table可以理解为SQL中的视图.
TableEnvironment提供了以下几个接口用于创建Table对象:
fromValues()from()sqlQuery()fromDataStream(),fromChangelogStream()
TableResult是Table.execute()和TableEnvironment.executeSql()的返回结果类型. Table.execute()返回的TableResult是对JobClient的封装, 后续可以从中取回执行结果. 而TableEnvironment.executeSql()返回的TableResult仅用于标识执行成功, 是一个只有一行一列的表, 其列名为result, 值为OK.
TableResult的实现关系如下图所示, 其核心实现在TableResultImpl中.
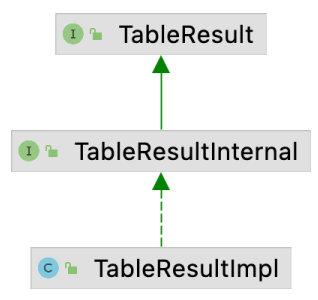
Table API & SQL核心实现模块
TableEnviroment是创建Table API和SQL程序的核心入口, 它提供了统一的用于处理有界和无界数据的接口. TableEnviroment主要负责:
- 注册并管理Catalog, Table, View以及Function等元素, 如
registerCatalog(),from(),createTemporaryView()和createFunction()等接口; - 执行SQL语句, 如
sqlQuery()和executeSql()接口.
TableEnviroment的继承关系如下图所示, 其中核心的实现逻辑在TableEnviromentImpl中. StreamTableEnviroment对TableEnviroment进行了扩展, 添加了Table与DataStream之间的转换接口, 如fromDataStream()和toDataStream()等.
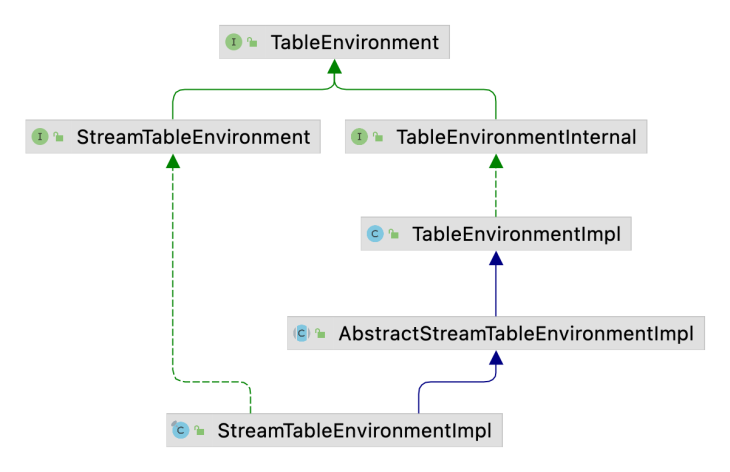
在纯Table API和SQL程序中建议使用
TableEnviroment, 如果需要在Table和DataStream之间转换, 则使用StreamTableEnviroment.
TableEnviroment的核心成员如下, 它正是组合使用这些核心成员来将Table API或SQL描述的Flink程序转化为Transformation并提交给Flink集群运行.
CatalogManager: 用于管理Catalog, 并提供了操作Table元数据的接口.FunctionCatalog: 用于管理UDF, 提供了函数的注册和删除接口. 长期来看它会被废弃, 相关的操作会合并到CatalogManager中.ModuleManager: 用于管理Module, 默认会加载CoreModule, 在Hive兼容模式下需要加载HiveModule.ResourceManager: 用于管理各种用户资源, 如依赖的Jar包, 文件等.TableConfig: 用于配置当前TableEnviroment会话.Executor: 提供了将Transformation图转化为StreamGraph, 以及执行StreamGraph的接口.OperationTreeBuilder: 用于将Table API中的各种操作转化为Operation.Planner: 用于将Operation翻译为Transformation图.
CatalogManager
CatalogManager用于管理Catalog, Table, View等对象. 在Flink SQL中, 存在类似于关系型数据库中从Cataog到Database到Table/View的层级关系, 每个上一级对象都可以包含多个下一级对象. CatalogManager借助Catalog管理Table和View.
Catalog
Catalog用于管理Database, Teble/View, UDF等元数据, 需要注意的是Catalog仅管理永久对象, 临时的Table/View或UDF分别由CatalogManager和FunctionCatalog管理.
Catalog的继承关系如下图所示:
- 默认情况下使用的是
GenericInMemoryCatalog, 即将所有元数据信息都保存在内存中. HiveCatalog支持与HiveMetaStore集成.AbstractJdbcCatalog的几个实现类并不支持创建对象, 主要是用于Flink CDC集成数据时获取MySQL或PostgreSQL中已有的表.
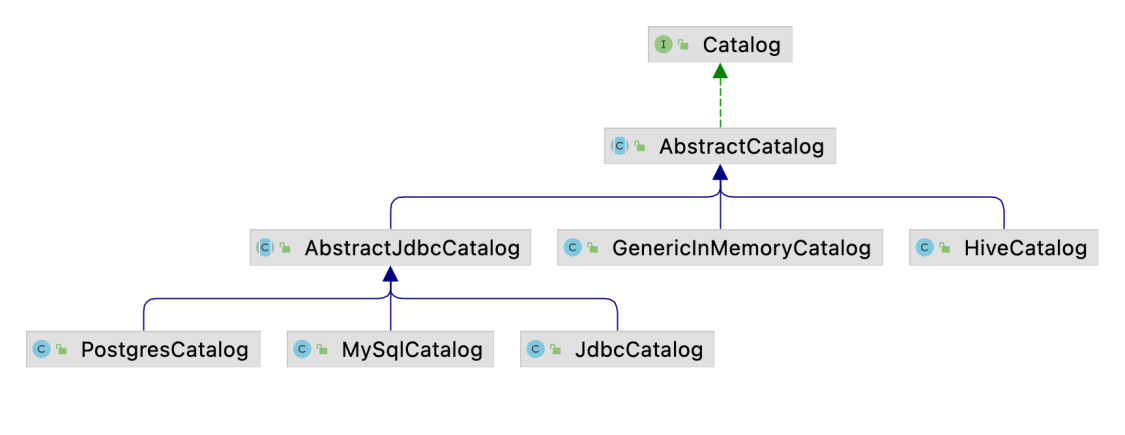
FunctionCatalog
FunctionCatalog的实现较为简单, 它直接管理临时UDF, 并借助Catalog管理永久UDF. 从长远来看, FunctionCatalog应当是CatalogManager的一部分.
ModuleManager
ModuleManager用于管理Mudule, 目前的Mudule支持扩展UDF, 未来可能会考虑支持扩展数据类型, 算子, 优化规则等. 默认情况下会加载CoreModule, Flink也实现了HiveModule以加载Hive内置的函数.
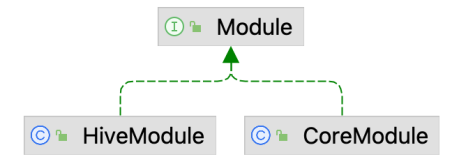
TableConfig
TableConfig用于配置当前TableEnviroment会话, 其配置加载顺序如下:
config.yaml文件中的配置;- 客户端启动时指定的参数;
StreamExecutionEnvironment中配置的参数;EnvironmentSettings.Builder.withConfiguration(Configuration),TableEnvironment.create(Configuration)创建的配置;- 通过
set(ConfigOption, Object) / set(String, String)配置的参数.
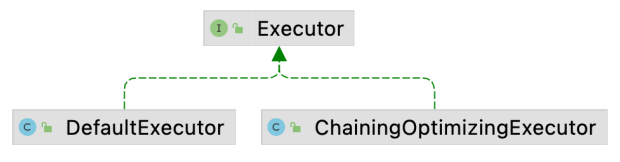
Executor
Executor用于执行Planner生成的Transformation图, 可将TableEnviroment与具体的运行时解耦. DefaultExecutor的实现逻辑比较简单, 即调用StreamExecutionEnvironment创建或执行StreamGraph.
OperationTreeBuilder
Flink在实现中为了统一处理Table API和SQL, 抽象了Operation接口.
- Table API中的各种操作, 如
project,aggregate,join等都会通过OperationTreeBuilder转化为QueryOperation. - SQL语句经过Calcite解析之后会转化为
PlannerQueryOperation, 其内部持有SQL语句转化来的RelNode树.
Planner
Planner是TableEnviroment中最核心的成员, 它主要有两个用处:
- 作为SQL解析器(通过
getParser()获取), 将SQL文本解析为Operation树; - 关系代数优化器, 将
ModifyOperation优化并转化为Transformation树.
Planner的两个实现类为StreamPlanner和BatchPlanner, 分别为流批作业执行优化, 在内部会使用不同的优化器.
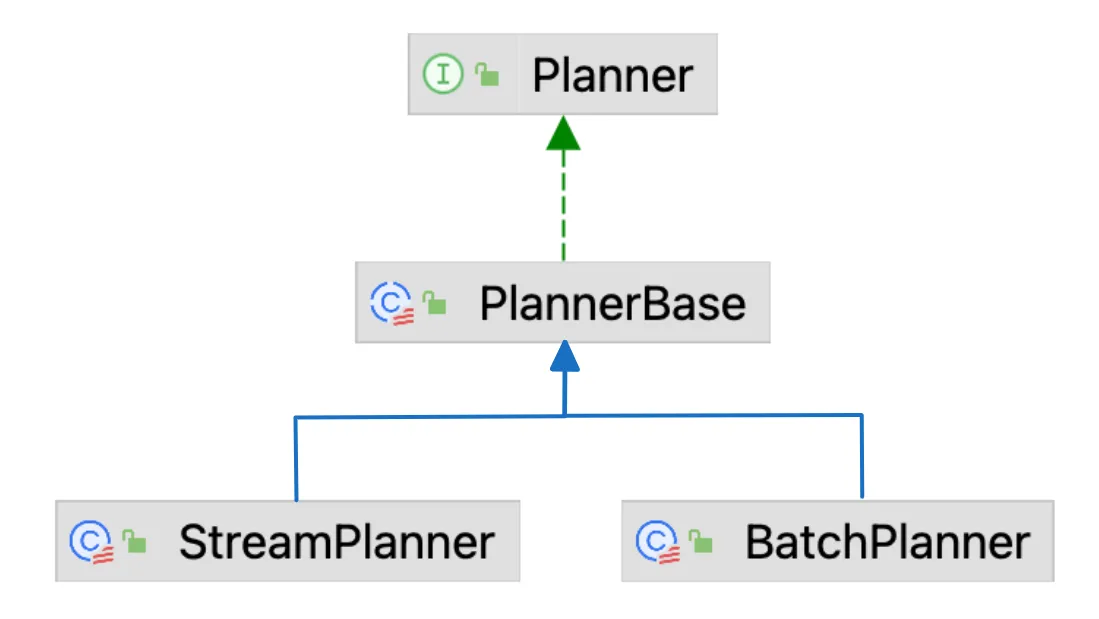
Table API & SQL执行流程
TableEnvironment/StreamTableEnvironment的创建流程
TableEnvironment和StreamTableEnvironment的创建流程基本一致, 分别在TableEnvironmentImpl和StreamTableEnvironmentImpl的create()方法中.
Table API最佳实践
上文介绍了与Table API和SQL执行相关的模块, 为了加深理解, 接下来我们通过一个案例来说明如何使用这些模块进行开发,以扩展现有API的能力.
如果要对Flink进行平台化, SQL脚本的执行是一个十分重要的能力, 但是目前开源Flink中的TableEnvironment并不支持直接执行SQL脚本. 为了实现执行SQL脚本的能力, 我们当然可以先将SQL脚本按分号分割, 然后调用TableEnvironment.executeSql(). 不过这种实现方式相对繁琐, 实际上Flink已经有了一个支持SQL脚本的解析器, 我们只需要稍加扩展就能实现SQL脚本的执行, 而无需编写繁杂的SQL解析代码.
完成本文的案例之后, 可以通过如下代码执行一个SQL脚本. 笔者提供的可运行示例见StatementsExample.
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
要实现上述功能, 我们只需要围绕Parser和TableEnvironment做一些扩展. 具体实现如下:
- 在
Parser接口中新增一个parseStatements()方法用于解析SQL脚本, 并在ParserImpl中实现该方法. 这里需要考虑的一点是,parseStatements()实际上进行了SQL解析和验证两个操作, 最终需要返回的是经过验证的Operation集合. 而对于SQL脚本而言, 后面的DML语句依赖于前面的DDL语句, 只有DDL语句对应的Operation执行完成后, DML语句才能通过验证. 因此parseStatements()不能直接返回List<Operation>, 比较合适的做法是返回一个Iterator<Operation>以实现延迟验证, 将验证的过程添加到Iterator<Operation>的迭代过程中. - 在
TableEnvironment中新增一个executeStatements()方法用于执行SQL脚本, 并在TableEnvironmentImpl中实现该方法.
为了实现上文所说的延迟验证, 并更好地处理Statement set, 我们添加一个OperationsConverter来帮助将SqlNode进行验证并转化为Operation. 其代码如下.
1 | public class OperationsConverter implements Iterator<Operation> { |
总结
本文从整体上介绍了Table API和SQL内部实现中的几个相关模块, 了解这些模块是进一步了解Flink Table API和SQL实现原理的基础. 这些模块经过精心的设计, 具有强大的扩展性, 基于这些抽象接口进行扩展开发, 可使得Flink支持更多的上下游组件.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送