本文是Hadoop YARN原理系列的第二篇, 主要讲述如何编写YARN Application. 实际上, MapReduce, Spark以及Flink等框架在YARN上运行时, 都可以视为一种特定的YARN Application. 不过这些系统的on YARN模式实现都是生产级别的, 代码相对复杂, 所以本文并不打算以这些系统的on YARN实现为例分析如何编写YARN Application, 而是以Hadoop自带的hadoop-yarn-applications-distributedshell(后文简称DistributedShell)为例进行讲述. DistributedShell可以在YARN的Container上执行用户指定的Shell命令或脚本, 虽然简单, 却包含了编写一个YARN Application的完整内容.
本文首先基于DistributedShell从整体上升分析YARN的工作流程, 然后讲述具体的代码实现. 所有相关的代码和运行方法都可以在此链接中找到.
YARN工作机制
从整体上来看, 一个YARN Application的提交和启动流程是这样的:
- 用户编写的Client向ResourceManager申请Application.
- ResourceManager返回所申请的Application相关信息.
- Client封装Application所需资源, 包括运行ApplicationMaster所需的资源和命令, 以及运行具体任务所需的相关资源等.
- ResourceManager启动一个Container并运行ApplicationMaster.
- ApplicationMaster负责申请运行任务所需的Container, 并封装其所需的资源和启动命令, 最后启动并监控Container的运行情况.
这其中, 需要用户实现的内容是Client和ApplicationMaster, 不同的应用会有不同的实现. 比如Hadoop MapReduce和Flink作业向YARN提交时, 就需要不同的Client和ApplicationMaster实现.
下面具体讲述DistributedShell在YARN上的具体提交和启动流程.
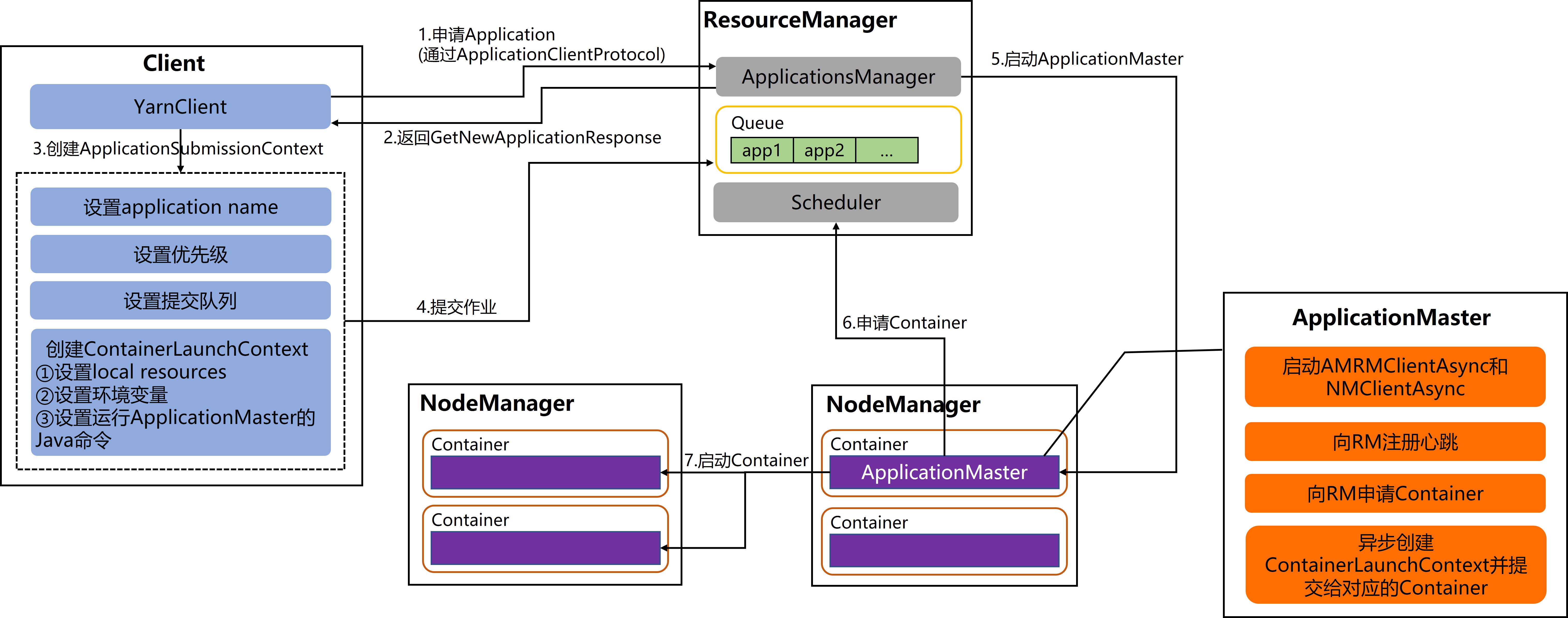
DistributedShell的提交和启动流程主要有以下几个步骤:
- 在Client中通过
YarnClient向ResourceManager的ApplicationsManager申请Application, 在内部这是由ApplicationClientProtocol封装的通信协议完成的. - ResourceManager会返回一个
GetNewApplicationResponse对象, 其中包含ApplicationSubmissionContext以及ApplicationId等. - Client创建
ApplicationSubmissionContext所需内容, 包括设置application name, 设置优先级, 设置提交队列并创建ContainerLaunchContext. - 最终Client会向ResourceManager提交Application到队列中.
- ResourceManager的ApplicationsManager向NodeManager申请Container, 并根据Client提供的
ContainerLaunchContext启动ApplicationMaster. - Application启动Container用于运行具体的任务.
YARN Application实现
从上面的分析中已经可以知道, 在编写YARN Application时, 需要我们自己实现的是两部分:
- 第一是Client, 主要用于接收用户命令, 向ResourceManager申请创建Application, 并提交相关资源.
- 第二是ApplicationMaster, 主要用于向ResourceManger申请创建用于工作的Container.
本节将具体讲述Client和ApplicationMaster的实现流程. 由于完整的实现包含大量的辅助代码, 所以这里只给出了核心代码用于梳理主要的实现流程, 对于完整的代码和运行方式可参考文章开头给出的链接.
Client实现
Client是运行在客户端的程序, 即会运行在向YARN集群提交Application的机器上. Client的实现主要包含以下几个核心步骤:
- 创建并启动
YarnClient; - 通过
YarnClient创建Application; - 完善
ApplicationSubmissionContext所需内容:
a. 设置application name;
b. 设置ContainerLaunchContext;
c. 设置优先级;
d. 设置队列 - 提交Application.
核心代码如下.
1 | Configuration conf = new YarnConfiguration(); |
这里的ContainerLaunchContext是用于启动ApplicationMaster的Container上下文环境, 其中包括:
localResources: 包含ApplicationMaster的Jar包, 一些本地文件, 以及需要运行的Shell命令等(这里需要注意的是, 如果用户给定的是一个Shell脚本, 那么这个脚本会被上传到HDFS, 而不会被作为本地资源上传);env: 包含ApplicationMaster运行所需的环境变量, 比如Shell脚本位置(用于创建任务Container), Java CLASSPATH等;commands: 运行ApplicationMaster的Java命令.
ApplicationMaster实现
ApplicationMaster运行在Container中, 其核心实现步骤如下:
- 创建并启动AMRMClientAsync, 用于与ResourceManager通信;
- 创建并启动NMClientAsync, 用于与NodeManager通信;
- 向ResourceManager注册, 之后会向ResourceManager发送心跳;
- 向ResourceManager申请Container.
1 | // 1. 创建并启动AMRMClientAsync, 用于与ResourceManager通信 |
其中, 用于运行任务的Container的启动逻辑是在AMRMClientAsync的回调接口里面的. 一旦ApplicationMaster向ResourceManager申请的Container创建成功后, 就会触发如下回调. 该回调会创建一个LaunchContainerRunnable线程并启动.
1 | public void onContainersAllocated(List<Container> allocatedContainers) { |
真正运行Container的逻辑在LaunchContainerRunnable线程中, 这其中的逻辑其实就是创建一个ContainerLaunchContext并提交给NodeManager, 只不过这里的ContainerLaunchContext是用于运行Shell命令的Container的上下文环境. 其流程与创建ApplicationMaster的ContainerLaunchContext是一致的, 这里不再赘述.
小结
本文首先介绍了DistributedShell的整体运行流程, 实际上Hadoop MapReduce, Flink等框架在YARN上运行时也符合这个流程. 然后从核心代码方面分析了编写一个YARN Application具体需要实现的内容: Client和ApplicationMaster. 实际上, 需要在YARN上运行不同的应用, 就是要实现这两部分内容. 相信理解了本文介绍的内容之后, 再去看Flink等框架中与在YARN中提交作业相关的源码就不会一头雾水了.
参考
[1] Hadoop: Writing YARN Applications
[2] Service oriented application hosted on YARN demo
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送