我在今年(2021年)参加了大数据和数据库开发相关的校招岗位招聘, 整个应聘流程包括春招的实习生招聘以及秋招的正式招聘, 最终获得了阿里/腾讯/Shopee/网易/华为/有赞等多家公司的实习或正式offer, 当然也收到过一家公司的拒信. 虽然网络上分享计算机相关岗位面试经验的文章已经浩如烟海, 但是这些经验大多针对后端开发和算法, 鲜有介绍大数据或数据库开发的应聘经验. 然而大数据或数据库开发虽也属于系统开发, 但是在技术栈上与后端开发还是有很大不同, 一般公司也会设立单独的岗位. 这也催生了我写这篇博文的想法, 本文主要分享以下内容:
- 大数据或数据库开发的工作内容究竟是什么?
- 大数据或数据库开发需要学习哪些内容? 面试会涉及哪些内容?
- 我的一些大数据或数据库开发面试经历.
本文的目的是希望帮助对数据工程研发感兴趣的同学明确应聘岗位, 理清学习路线, 并分享我自己的面试经历以供参考. 本文不会介绍具体的面试技巧, 比如如何进行自我介绍, 如何介绍项目或论文以及如何进行白板编程. 这些内容在”剑指Offer”或参考[1]中都有不少描述. 在正式开始之前, 还是需要进行免责申明, 由于本人水平有限, 很多观点局限于我的个人经历, 难免会有不当或错误, 希望见谅, 也欢迎指正.
岗位介绍
在前文中我并没有严格区分大数据和数据库开发, 虽然二者都是进行与数据存储和计算相关的系统开发, 从一定程度上来说都可以归为数据工程研发的大类, 但是就目前来看二者还是对应了不同的岗位, 开发内容也有所区别. 为方便描述, 在下文中我将使用数据工程研发代指各类与大数据组件或平台相关的开发, 而用数据库开发代指数据库内核开发. 尽管数据工程研发在一定程度上包含了数据库开发, 但是就目前来说数据库开发相对而言是更偏基础且独立的岗位.
首先看数据工程研发, 在公司的招聘网站上对应的岗位一般是大数据开发工程师/大数据平台开发工程师/数据工程师等. 这里需要注意的是某些公司可能还有类似数据研发的岗位, 一般来说数据研发和数据工程研发是有一定区别的, 数据工程研发关注的是底层数据存储和处理引擎或数据平台的研发, 属于系统研发的范畴, 而数据研发更多的是指依据业务进行数据建模, 或提供数据分析支持. 数据研发需要借助数据工程研发形成的数据平台. 当然有些公司并没有分的这么详细, 可能数据研发也包括了一些平台类的建设工作, 具体还是要仔细阅读职位描述.
以下是我从字节跳动和Shopee校招官网摘录的2021年校招数据工程研发相关职位的职位描述.
 2021年字节跳动数据工程研发校招职位描述
2021年字节跳动数据工程研发校招职位描述
 2021年Shopee数据工程研发校招职位描述
2021年Shopee数据工程研发校招职位描述
从中可以看出, 数据工程研发大致包括以下工作内容:
- 最底层的是各类开源大数据组件的开发和维护, 这类工作需要对某个开源组件有源码级的深入了解, 难度较大;
- 底层引擎之上就是公司内部数据平台的搭建, 比如统一的SQL查询平台, 机器学习平台等;
- 再往上就是基于现有的引擎和平台进行业务相关的数据链路开发, 这涉及到链路的架构设计以及基础组件的技术选型等;
- 最后就是数据仓库的设计与开发, 涉及数据建模和相关工具的开发.
再来看数据库开发. 一般所说的数据库开发都是指数据库内核开发, 数据库内核是一个非常复杂而庞大的系统, 专业程度极高, 不过对于校招而言一般不会要求有相关的开发经验. 但是从各个公司的职位介绍和面试情况来看, 对这一岗位的要求是比较高的. 这类岗位一般使用C/C++/Go语言进行开发, 需要对底层的操作系统, 计算机网络, 编译原理以及分布式理论有较深入的理解.
以下是我从智庾科技和PingCAP公司校招官网摘录的2021年数据库研发相关的职位的职位描述. 这两家公司目前在数据库领域都有出色的产品, 智庾科技的时序数据库DolphinDB在DB-Engins上也有不错的排名, PingCAP的TiDB是开源领域优秀的NewSQL和HTAP数据库.
 2021年DolphinDB数据库开发校招职位描述
2021年DolphinDB数据库开发校招职位描述
 2021年PingCAP数据库开发校招职位描述
2021年PingCAP数据库开发校招职位描述
面试内容
技术面试是十分具有技巧性的, 在开始之前进行一些训练能够在面试中更加游刃有余. 不过本文并不打算讲述面试技巧, 因为技巧虽然有用, 但是最重要的还是实力. 如果我们对面试岗位所需的技术有深入的了解, 那么配以一些最基本的经验, 我们基本就能通过面试. 本文主要讲述面试的内容, 我认为掌握这些内容是面试通过的关键. 这里将面试内容分为两部分: 一是计算机基础, 这无论对开发岗还是算法岗都是通用的; 二是数据系统的相关理论和技术, 这主要针对数据工程研发和数据库开发. 这里所述的内容基本上包含了数据工程研发所需的全部知识, 在相关内容之后我会说明在面试中的出现频率. 不过学习的目的从来都不是通过面试, 而是真正的掌握这些内容, 可以使自己在未来的职业生涯中有更好的发展.
计算机基础
关于计算机基础, 我习惯将其分为两大部分内容.
- 一部分是编码相关的内容, 这部分直接与日常的编码相关, 包括:
- 编程语言, 是编写代码的基本工具, 至少需要熟悉一到两门编程语言, 在面试中可能会考察一些编程语言的基础内容, 包括语法, 关键字, 标准库等. 对于数据工程研发可能会涉及SQL语言.
- 数据结构与算法, 这是编写高效代码的关键, 也是面试考察的重中之重, 一般技术岗面试每轮都会考察1-2题白板编程题.
- 设计模式, 如果说利用数据结构和算法可以编写更高效的代码让计算机运行的更快, 那么利用设计模式就可以编写更优雅和易于维护的代码让程序员更好的理解和维护. 前者的高效是对机器而言, 后者的高效是对人而言.
- 另一部分是与计算机原理相关的, 这部分看似与编码不直接相关, 但却是写出高效代码的关键, 特别是对于系统开发而言, 了解计算机原理是编写正确代码的关键. 这一部分包括:
- 计算机组成原理
- 操作系统, 了解操作系统原理, 对于并发编程有重要作用.
- 计算机网络
- 编译原理, 数据库或大数据框架的SQL解析背后都涉及到编译原理的知识.
- 数据库, 对于数据工程或数据库研发这是必须具备的知识, 本文会在数据系统中更具体的讲述.
在面试中, 上述各个部分的出现频率的排序大概是: 数据结构与算法>操作系统>计算机网络>=数据库>设计模式. 其中计算机组成原理和编译原理一般不会出现, 如果准备时间紧迫可以按面试出现频率准备, 如果时间充分的话可以进行全面的复习总结.
数据系统
数据系统这个词实际上是笔者总结的, 并没有官方的定义. 目前与数据存储和计算相关的系统有两大类:
- 一类是业界常说的大数据系统, 这类系统通常一个组件负责单一的存储或计算功能, 要实现一个完整的数据分析平台需要组合多个组件. 比如一种常见的技术架构是采用Sqoop将线上关系型数据库的数据导入到HDFS, 然后使用Hive或Spark进行分析.
- 另一类是数据库系统, 分为OLTP和OLAP, OLTP专注于线上业务, OLAP专注于分析业务. OLAP数据库系统集成了大数据存储和计算功能.
不管是大数据系统还是数据库系统, 其本质上都是用于数据存储和计算的数据系统, 当然随着数据量的不断增大, 目前这些系统多数都是分布式数据系统. 实际上, 在数据系统的最早期, 数据量较小, 因此一个单机的数据库系统就可以承担所有的在线业务和分析业务, 比如在百万行数据时, 一个MySQL实例即可承担所有的数据存储和分析任务. 但是随着数据量的增大, 这时候又没有一个可以进行大规模数据分析任务的数据库系统, 因此就衍生了一系列大数据系统, 它们有的负责数据的采集传输, 有的负责数据的存储, 有的负责数据的计算. 但是随着分布式技术的发展, 大家发现这些大数据系统种类繁多部署复杂, 所以又开始回归数据库系统, 现在越来越多的分布式OLAP数据库支持大数据的存储和计算服务. 笔者也认为未来的数据系统会越来越向数据库系统方向发展, HTAP会成为一个重要的发展方向.
当然, 不论是大数据系统和数据库系统, 其本质上都是分布式数据系统, 它们都有分布式系统的特点, 同时用于解决存储和计算问题. 以下是对常用大数据或数据库系统的总结.
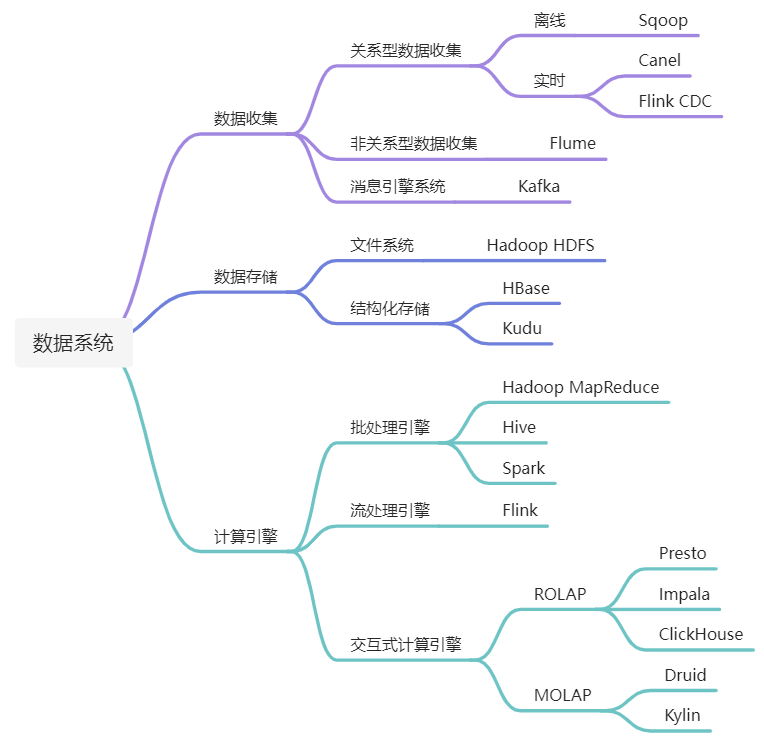
学习路线
如果在Google上搜索”大数据学习路线”, 出现的内容浩如烟海. 不过这些内容大多有一个共同的特征, 那就是无休止的罗列相关大数据相关框架的教学视频和学习资料. 这些资料确实有一定的参考价值, 但也仅限于让我们了解当前主流的大数据框架以及在需要具体学习某个框架时提供一些入门的资料. 事实上, 这些学习路线太过于大而全了, 对于校招而言, 公司一般不会要求熟练使用所有的框架, 而是希望面试者精通其中的某个或少数几个框架, 掌握其背后的原理, 并能举一反三了解一类框架设计的初衷和所能解决的本质问题. 笔者认为正确的学习过程应该是这样的:
- 建立全局意识, 首先了解目前的大数据技术体系, 了解哪些框架解决的是同一类问题, 这时可以浏览一下网上现有的大数据学习路线, 尚硅谷的2021年度全网最全大数据学习路线是一个相对不错的参考, 我在上一节中总结的数据系统结构图也是个不错的参考;
- 钻进去, 了解细节. 这时候需要选择一个具体的框架进行学习, 如果平时有项目可选择与项目相关的框架, 如果没有项目可选择热门的框架进行学习. 如计算框架Spark, Flink或存储框架HBase, 一般某种类型选择一个框架学习即可.
- 返璞归真, 重回本质. 在了解了几类具体框架的使用或实现原理之后, 应当回过头来看看这些框架背后的本质是什么, 以及为什么需要这么实现.
对于数据工程研发, 笔者认为比较合适的学习路线应该是这样的:
- 学习关系型数据库的使用和原理, 选择一个数据库进行学习, 如MySQL. 关系型数据库是数据存储与处理技术的起源, Spark, Flink等大数据处理框架也越来越推崇SQL化, 我认为学习大数据系统关系型数据库的知识越多越好, 这方面可参考:
- 学习Hadoop框架, 尽管现在Hadoop在生产环境中使用越来越少, 但是作为大数据系统的开端还是有必要学习. 重点是掌握HDFS, YARN和MapReduce背后的设计哲学, 尽可能阅读相关论文. 这方面可参考:
- 学习一个计算框架, 目前Flink有一统批流计算的趋势, 如果非项目需要可学习Flink, 如果项目主要是批处理可选择Spark. 同样, 尽可能阅读相关论文. 这方面可参考:
- 学习一个分布式数据库, 目前分布式数据库种类繁多, 有OLTP也有OLAP, 可先选择一个进行深入学习, Hadoop生态中推荐HBase. 这方面可参考:
- 学习分布式系统的相关理论. 目前的大数据系统本质上都是分布式数据系统, 要真正理解这些系统的运行原理, 分布式系统的理论是必不可少的. 这方面可参考:
- 有了上面这些前置知识之后, 基本上对大数据框架的类别和实现原理做到心中有数了. 这时候可以进一步将知识体系化, 这方面可参考:
关于数据库开发的学习路线可参考Database Development Learning Map.
应聘经历
我的整个校招持续了接近一年的时间(从2020年12月到2021年9月), 包括春招实习生招聘和秋招正式招聘, 以及中间接近三个月的实习经历. 春招的面试经历及之后的实习经历对秋招有重要的作用, 所以对于找工作的同学来说, 因当从春招找实习开始就有充分的准备.
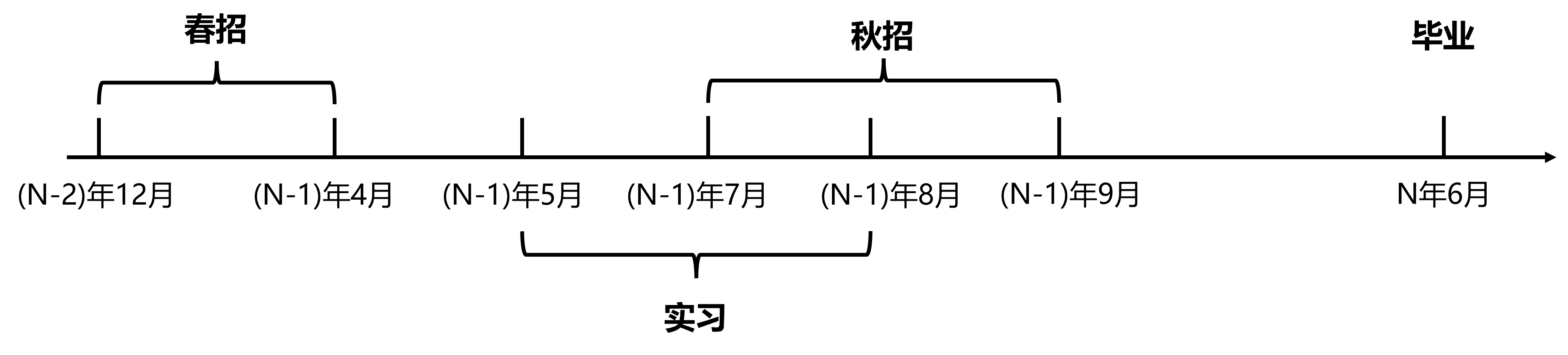
上图概括了一般互联网公司的整个应届生招聘时间线, 跨度接近10个月.
需要说明的是, 这里的时间线是对于互联网公司而言的. 互联网公司春招一般不招聘应届生, 只招聘实习生. 一般来说秋招的正式offer有一部分会发给实习生. 其他行业春招秋招可能都会招聘应届生.
对于春招拿到offer的同学来说, 一般可以在5-8月份选择3个月左右的时间进行实习. 公司一般欢迎尽早实习尽可能长的时间, 对于个人来说有机会也应当尽可能早的出去实习. 一方面可以积累工作经验, 另一方面实习很有可能转正, 这也是一个提前熟悉工作环境的机会.
在实习的过程中, 一些公司的秋招提前批就会陆续开放简历投递. 最早的在7月初就会开放, 多数应该在7月底8月初开放. 对于实习开始比较晚的同学, 这时候实习可能刚刚开始, 相对来说就比较难以权衡, 究竟是认真完成实习工作争取更多产出, 在转正中拿到不错的评价; 还是选择多面几家公司选择更合适自己的. 对于实习开始早的同学, 这时候一般实习已经接近尾声, 可以选择适当投递几家合适的公司进行面试.
在9月份, 秋招会迎来最后一波高潮, 一般这时候实习已经结束了, 大部分公司的秋招都还在进行中, 如果目前还没有十分满意的offer, 可以选在在9月份进行最后的冲刺.
虽说是金九银十, 但实际上9月过后, 一般之后极少数的互联网公司还会进行面试. 10月中下旬, 大多数的公司会发放谈薪并发放正式的offer. 在11月份可能还有少数公司会进行一轮的秋招补招.
这里我也分享一下我的秋招面试经历, 由于我的Base地已经确定是杭州, 因此投递的大多是杭州的岗位.
如何看待面试
实际上, 在面试开始之前, 我们需要认识到面试的本质, 摆正心态, 才能真正从面试中获得我们所需要的东西. 关于如何看待面试, 我想分享以下两点.
首先, 面试是一个双向选择的过程. 面试的过程不仅是让面试官了解你, 也是你了解面试官以及工作岗位的过程. 虽然在投递简历时一般会有简单的职位描述, 但是从面试官口中可以了解更加具体的工作内容, 以及面试官本人的工作感受, 这都可以作为评判面试岗位的进一步参考. 另外, 面试官一般就是入职之后的同事或leader, 通过在面试中的沟通顺畅程度, 你可以判断能否与将来的同事和谐共处. 通常面试的最后环节, 面试官都会给机会让你反问几个问题, 这是一个需要特别把握的机会, 特别是对于秋招而言, 在正式入职之前对于工作岗位的了解最多的就是来自于面试官. 我一般会咨询一下部门的组织架构和人员组成情况, 部门的主要工作内容和支撑业务, 以及面试官本人的工作感受和挑战.
其次, 面试不要害怕失败, 事后要及时复盘. 面试失败是常有的事, 通常每轮面试只会进行一个小时的时间, 在这一个小时内是很难完全展现自己的能力的. 当遇到一些没有经验的面试官时, 面试者只能按照既定的套路回答问题, 这其实存在很大的偶然性和运气. 当然, 也有一些面试官经验丰富, 可以从谈话中找到你感兴趣和擅长的点并不断深入. 所以即使面试失败也不要自我否定, 不论成功还是失败, 我们要做的都是及时复盘. 如果有条件的话可以将面试过程录音, 在事后复盘时要重点挖掘技术上薄弱的部分, 分析成功或者失败的原因, 这样才能不断的从实际面试中积累经验, 在未来更加从容的面对面试.
小结
本文首先对大数据和数据库开发的岗位进行了详细的介绍, 希望可以帮助相关方向的同学明确职业目标. 然后介绍了技术面试的基本内容以及数据工程研发的学习路线, 希望可以帮助希望从事数据研发的同学厘清学习内容. 最后分享了我的应聘经历, 可以帮助读者更好的把握应聘的时间节点, 提前做好准备.
其实数据工程研发本质上是与数据存储和计算相关的系统研发, 尽管目前多数框架给我们提供了完善的API, 但是掌握计算机的基础理论知识仍旧可以使我们不断收益. 在学习过程中也切勿忘记探究背后的本源, 框架总有过时的时候, 那些设计思想却在不断延续, 掌握背后的本质才能帮助我们走的更远.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送