Apache HBase能够在大数据集上为我们提供随机, 实时的读写访问. 然而, 在实际业务中, 我们的原始应用并非基于HBase构建. 这时候, 如何将大量的数据(这些数据的存储量可能是TB甚至PB级别的)导入到HBase中成了我们首先需要解决的问题. 最基本的, 我们可能会想到使用Client APIs或利用MapReduce Job通过TableOutputFormat写入. 然而, 这两种方式都不是最高效的, 在向HBase中导入大规模数据集时, 首先应该考虑的是HBase提供的Bulk Loading方法.
但是, 在利用Bulk Loading向HBase中导入数据时, 常常会遇到很多困难. 一方面是由于HBase的官方指南仅给出了一些关于Bulk Loading的原理说明, 并没有给出代码示例; 另一方面Bulk Loading涉及到一些底层的原理(比如数据的排序是如何进行的, 数据是如何分区的), 如果不了解这些原理就难以写出高效的Bulk Loading程序. 此外, 通过MapReduce对数据进行预处理并使用HFileOutputFormat2.configureIncrementalLoad对数据进行全局排序的方法并不能最大限度的利用集群的计算能力, 无论如何目前已经很少有人还在编写MapReduce程序, 取而代之的是Spark. 为此, HBase官方推出了Apache HBase Connectors支持Spark与HBase的连接, 提供了基于Spark的bulk put/get/delete/load等操作, 但是HBase Connectors仅支持2.2.x版本的HBase.
本文首先讲述HBase Bulk Loading的原理以及为甚么需要使用Bulk Loading, 最后讲述如何基于Spark在1.4.x系列版本上利用Spark而非HFileOutputFormat2.configureIncrementalLoad进行更加高效的Bulk Loading, 同时也给出了在2.2.x系列版本上使用HBase Connectors进行Bulk Loading的示例.
Bulk Loading原理
简单来说, Bulk Loading即通过MapReduce或Spark等分布式计算框架对大规模数据集进行预处理和排序, 输出为HBase的底层存储文件HFile, 最终通过HBase提供的LoadIncrementalHFiles.completebulkload工具将输出的HFile移动到RegionServer对应Region的存储文件夹中, 从而完成数据导入. 事实上, Bulk Loading的过程与ETL类似, 主要包含以下几个步骤:
1. Extract: 从数据源中导出数据, 一般为文本文件或其他数据库的dump文件. 如何从数据源中导出数据并不在本文的讨论范围之内, 一般来说现有的数据库都支持各种类型的导出, 也可以很方便地通过MapReduce或Spark提供的接口进行读取. 在进行下一步之前, 需要提前将数据源文件上传到HDFS中.
2. Transform: 将原始数据处理排序并重写为HFile. 本文利用Spark进行这一步操作, 具体流程如下(HBase Connectors中的实现类似):
- 读取并解析原始文件, 通常需要读者自行编写解析函数, 从原始文件生成RDD;
- 通过Spark的
repartitionAndSortWithinPartitions函数对RDD进行重分区和排序, 笔者提供了类BulkLoadPartitioner用于重分区, 类KeyFamilyRow用于根据row key, column family, column qualifier对记录进行全局排序; - 将RDD通过Spark的
saveAsNewHadoopFile写为HFile文件;
这一步中有几个细节值的说明. 首先,
BulkLoadPartitioner进行重分区的分区数量等于HBase table中存在的Region数量(仅针对未进行预分区的table, 对于预分区的table则分区数等于table的预分区数), 也就是说, 对于一个未进行预分区的空table, 在利用Spark进行repartition后只会有一个分区, 这可能会影响生成HFile的效率. 然而读者应当慎重改变RDD分区的数量, 虽然这可能提升生成HFile的效率, 但是这可能导致无法确定生成的HFile应当加载到哪个RegionServer中. 其次, 本文的方法利用saveAsNewHadoopFile将RDD输出为HFile, HBase Connectors中采用了自定义的方法, 具体可参见HBaseContext.scala中的bulkLoad函数.
3. Load: 将生成的HFile导入RegionServer相应的目录中. 调用LoadIncrementalHFiles.completebulkload将HFile导入RegionServer中, 并使数据对客户端可见. 在调用completebulkload前如果有新数据插入, 或者Region split发生, 则completebulkload会根据当前table的Region起止row key范围, 重新对HFile进行分割. 这并不是高效的, 因此应当避免目标table在生成HFile的过程中有较大变动. 此外, completebulkload并不是线程安全的, 切勿对同一个表同时调用此函数.
Bulk Loading的过程如下图所示. 数据从源导入HDFS中, 通过Spark定义的DAG操作进行处理生成HFile. 最后将HFile移动到对应的RegionServer.
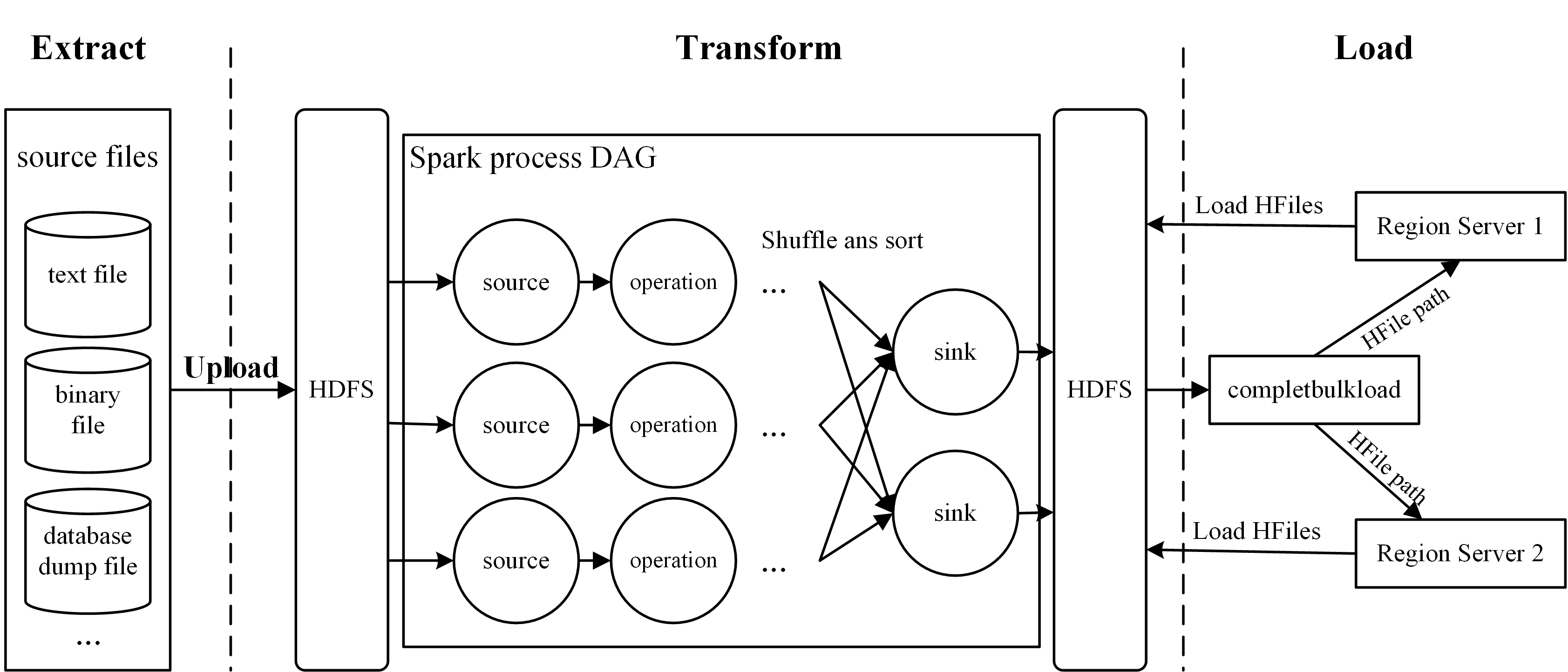
使用Spark实现Bulk Loading
在HBase 2.2.x版本中HBase官方推出了HBase Connectors, 提供了Spark, Kafka与HBase的各种交互操作. 其中包括利用Spark进行Bulk Loading. 然而, HBase Connectors并不兼容HBase 1.4.x系列, 为此本文提供了一个利用Spark在1.4.x版本上进行Bulk Loading的例子, 根据该例读者只需利用Spark重写源文件处理操作即可.
HBase 1.x中的Bulk Loading
在HBase 1.4.x中利用Spark进行Bulk Loading需要自定义分区及排序逻辑, 作者提供了通用的实现. 分区实现见BulkLoadPartitioner, 排序实现见KeyFamilyQualifier. 在此基础上, 便可根据Spark现有的API函数实现Bulk Loading. 以下是一个简单例子的部分代码, 完整代码可参见HBaseSparkBulkLoad.
1 | // get table info |
HBase 2.x中的Bulk Loding
在HBase 2.2.x中可利用HBase Connectors提供的API更加方便地实现Bulk Loading. 以下是一个简单的案例, 完整的实现可参考JavaHBaseBulkLoadExample.
1 | SparkConf sparkConf = new SparkConf().setAppName("JavaHBaseBulkLoadExample " + tableName); |
参 考
[1] Apach HBase ™ Reference Guide 72 110
[2] How-to: Use HBase Bulk Loading, and Why
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送