本文首先结合HBase过滤器的源码, 讲述HBase过滤器抽象基类Filter中各个函数的作用. 最终给出一个简单的自定义过滤器的案例, 在此基础上分析了Filter中各个方法的执行流程, 读者在理解该案例的基础上可以编写任何个性化的过滤器. 本文涉及的源码基于HBase 1.4.x.
HBase自定义过滤器能够在RegionServer上, 执行更加复杂和个性化的过滤操作. 例如, 在利用HBase存储时空数据时, 可以将时空范围的过滤操作放到过滤器中. 使用过滤器主要有以下两个优点:
一是通过使用过滤器将过滤逻辑放到RegionServer上执行, 可以使客户端代码更加简洁;
二是将过滤操作放到RegionServer上执行可以减少网络传输, 提升查询效率.
当然, 使用自定义过滤器也存在一定的缺点: 过滤器对象需要在HBase的Client和RegionServer之间通过网络传输, 对于用户自定义过滤器, 需要重写序列化和反序列化操作, 不同于Go语言, Java语言并没有提供原生的高效序列化支持, HBase预定义的过滤器使用了Protocol Buffers 进行序列化与反序列化. 本文给出的案例使用了Java的NIO进行自定义过滤器对象的序列化和反序列化, 在生产环境中建议使用Protocol Buffers.
HBse自定义过滤器概览 HBase过滤器属于客户端API, 相关的源码均在hbase-client模块的org.apache.hadoop.hbase.filter包 下. 对于设定了过滤器的scan操作, 在每个Region上过滤器都会起作用.
自定义HBase过滤器需要继承抽象类Filter或抽象类FilterBase. Filter是FilterBase的基类, FilterBase为我们提供了一些方法的默认实现, 在自定义过滤器时可先继承FilterBase, 实现其抽象方法, 在需要更进一步的个性化操作时再考虑按需实现Filter提供的方法.
在具体探讨HBase过滤器之前, 我们将首先探讨抽象类Filter中各个函数的作用, 理解这些函数的具体作用是我们进行后续研究的基础. 类Filter 的定义如下, 这里为每个属性和函数添加了详细的注释, 解释其作用.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 public abstract class Filter protected transient boolean reversed; abstract public void reset () throws IOException abstract public boolean filterRowKey (byte [] buffer, int offset, int length) throws IOException ; abstract public boolean filterAllRemaining () throws IOException abstract public ReturnCode filterKeyValue (final Cell v) throws IOException abstract public Cell transformCell (final Cell v) throws IOException @Deprecated abstract public KeyValue transform (final KeyValue currentKV) throws IOException public enum ReturnCode { INCLUDE, INCLUDE_AND_NEXT_COL, SKIP, NEXT_COL, NEXT_ROW, SEEK_NEXT_USING_HINT, INCLUDE_AND_SEEK_NEXT_ROW, } abstract public void filterRowCells (List<Cell> kvs) throws IOException abstract public boolean hasFilterRow () abstract public boolean filterRow () throws IOException @Deprecated abstract public KeyValue getNextKeyHint (final KeyValue currentKV) throws IOException abstract public Cell getNextCellHint (final Cell currentKV) throws IOException abstract public boolean isFamilyEssential (byte [] name) throws IOException abstract public byte [] toByteArray() throws IOException; public static Filter parseFrom (final byte [] pbBytes) throws DeserializationException throw new DeserializationException( "parseFrom called on base Filter, but should be called on derived type" ); } abstract boolean areSerializedFieldsEqual (Filter other) public void setReversed (boolean reversed) this .reversed = reversed; } public boolean isReversed () return this .reversed; } }
通过上述对Filter中函数原型的解释, 可以有以下几点结论:
一般真正包含过滤逻辑的函数只有两个: filterRowKey与filterKeyValue;
如果只需对row key进行自定义的过滤, 那么继承FilterBase, 在filterRowKey中重写row key相关的过滤逻辑即可;
如果只需对column qualifier或value进行过滤(对column family的过滤一般调用Scan类的函数), 那么继承FilterBase, 在filterKeyValue中重写与cell相关的过滤逻辑即可;
如果既需要对row key进行过滤又需要对column qualifier或value进行过滤, 则需要同时重写filterRowKey和filterKeyValue中的过滤逻辑.
HBase过滤器执行流程 在对HBase过滤器基类Filter中的各个函数有了一定了解之后, 我们再通过一个实际的自定义过滤器类来研究过滤器的执行流程. 自定义过滤器的原型如下, 隐去了部分辅助函数, 完整的代码可参看CustomFilter.java . 这个自定义过滤器用于选取row key前缀与给定前缀相同, 且column family, column qualifier, value与给定值相等的cell.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 public class CustomFilter extends FilterBase private static Logger logger = LoggerFactory.getLogger(CustomFilter.class ) ; private boolean filterRow = true ; private boolean passedPrefix = false ; private byte [] prefix; private byte [] cf; private byte [] cq; private byte [] value; public CustomFilter (final byte [] prefix, final byte [] cf, final byte [] cq, final byte [] value) logger.info("Constructor method is called, row prefix: " + new String(prefix) + ", column family: " + new String(cf) + ", column qualifier: " + new String(cq) + ", value " + new String(value)); this .prefix = prefix; this .cf = cf; this .cq = cq; this .value = value; } @Override public void reset () logger.info("reset() method is called" ); filterRow = true ; } @Override public boolean filterRowKey (byte [] buffer, int offset, int length) logger.info("filterRowKey() method is called" ); if (buffer == null || this .prefix == null ) return true ; if (length < prefix.length) return true ; int cmp = Bytes.compareTo(buffer, offset, this .prefix.length, this .prefix, 0 , this .prefix.length); if ((!isReversed() && cmp > 0 ) || (isReversed() && cmp < 0 )) { passedPrefix = true ; } filterRow = (cmp != 0 ); return filterRow; } @Override public boolean filterAllRemaining () logger.info("filterAllRemaining() method is called, passed prefix: " + passedPrefix); return passedPrefix; } @Override public ReturnCode filterKeyValue (Cell cell) logger.info("filterKeyValue() method is called, cell: " + cellToString(cell)); if (filterRow) return ReturnCode.NEXT_ROW; if (!(Bytes.equals(CellUtil.cloneFamily(cell), cf))) { return ReturnCode.NEXT_COL; } if (!(Bytes.equals(CellUtil.cloneQualifier(cell), cq))) { return ReturnCode.NEXT_COL; } if (!(Bytes.equals(CellUtil.cloneValue(cell), value))) { return ReturnCode.NEXT_COL; } return ReturnCode.INCLUDE_AND_NEXT_COL; } @Override public Cell transformCell (Cell cell) logger.info("transformCell() method is called, cell: " + cellToString(cell)); return cell; } @Override public void filterRowCells (List<Cell> list) logger.info("filterRowCells() method is called, size: " + list.size()); } @Override public boolean hasFilterRow () logger.info("hasFilterRow() method is called" ); return false ; } @Override public boolean filterRow () logger.info("filterRow() method is called, filterRow: " + filterRow); return filterRow; } @Override public Cell getNextCellHint (Cell cell) logger.info("getNextCellHint() method is called, cell: " + cellToString(cell)); return null ; } @Override public boolean isFamilyEssential (byte [] bytes) logger.info("isFamilyEssential() method is called, param: " + new String(bytes)); return true ; } }
为了研究上述自定义过滤器的执行流程, 我们建立一个简单的HBase表, 表名为filter_test, 包含f1, f2两个column family. 为了便于查看RegionServer的日志, 我们仅向filter_test表中插入两行数据. 建表及插入数据命令如下.
1 2 3 4 5 6 7 8 9 create 'filter_test', 'f1', 'f2' put 'filter_test', '150501', 'f1:a', '12' put 'filter_test', '150501', 'f1:b', '13' put 'filter_test', '150501', 'f1:c', '13' put 'filter_test', '150501', 'f2:d', '87' put 'filter_test', '150601', 'f1:a', '18' put 'filter_test', '150601', 'f1:b', '19' put 'filter_test', '150601', 'f1:c', '20' put 'filter_test', '150601', 'f2:d', '12'
在HBase shell中执行scan 'filter_test'可看到以下记录:
1 2 3 4 5 6 7 8 9 ROW COLUMN+CELL 150501 column=f1:a, timestamp=1583499565071, value=12 150501 column=f1:b, timestamp=1583499565085, value=13 150501 column=f1:c, timestamp=1583499565089, value=13 150501 column=f2:d, timestamp=1583499565093, value=87 150601 column=f1:a, timestamp=1583499565099, value=18 150601 column=f1:b, timestamp=1583499565104, value=19 150601 column=f1:c, timestamp=1583499565108, value=20 150601 column=f2:d, timestamp=1583499565112, value=12
在完成以上准备工作后, 我们便可以编写客户端代码来调用我们编写的自定义过滤器. 以下是主要的代码, 完整的代码请参考FilterExample.java . 这段代码用于在filter_test表中筛选row key前缀为1506, column family为f1, column qualifier为d, value为12的cell.
1 2 3 4 5 6 7 8 9 10 11 Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf("filter_test" )); Scan scan = new Scan(); scan.setFilter(new CustomFilter("1506" .getBytes(), "f2" .getBytes(), "d" .getBytes(), "12" .getBytes())); ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { for (Cell cell : result.rawCells()) { System.out.println(cellToString(cell)); } }
上述代码的运行结果如下, 可以看到, 使用过滤器之后过滤操作已经在RegionServer端完成, Client只需接收数据即可.
1 row key: 150601, family: f2, qualifier: d, value: 12
在CustomFilter中, 我们在每个函数体中都打印了调用日志, 在HBase RegionServer的日志中我们可以看到如下类似的记录. HBase的RegionServer日志在${HBASE_HOME}/logs路径下, 其中${HBASE_HOME}为HBase安装路径.
1 2 3 4 2020-03-08 20:59:56,950 INFO [RpcServer.default.FPBQ.Fifo.handler=29,queue=2,port=16201] filter.CustomFilter: parseFrom() method is called 2020-03-08 20:59:56,950 INFO [RpcServer.default.FPBQ.Fifo.handler=29,queue=2,port=16201] filter.CustomFilter: Constructor method is called, row prefix: 1506, column family: f2, column qualifier: d, value 12 2020-03-08 20:59:56,953 INFO [RpcServer.default.FPBQ.Fifo.handler=29,queue=2,port=16201] filter.CustomFilter: isFamilyEssential() method is called, param: f1 ...
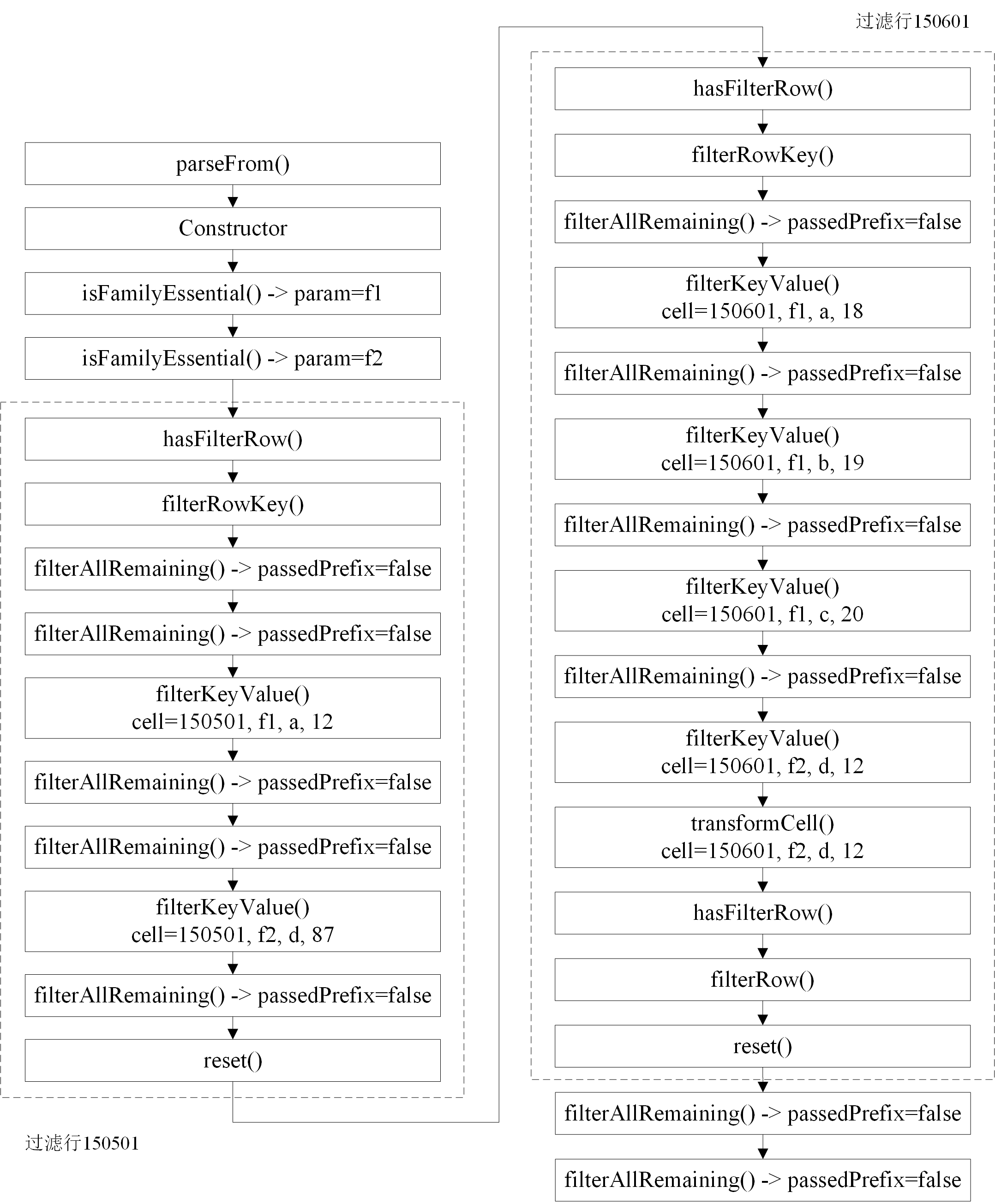
下图是根据RegionServer日志整理的CustomFilter中各个函数的执行流程.
从图中我们可以观察到以下几点:
在RegionServer上, 首先会调用parseFrom()函数将Client传来的过滤器二进制数组解析为过滤器实例;
isFamilyEssential()函数在过滤器构造完成后即调用, 针对表中的每个column family均会调用一次;在对每一行的过滤中, 主要的过滤逻辑由filterRowKey()和filterKeyValue()两个函数完成, 对于经过filterKeyValue()过滤而决定保留的cell, 都会调用transformCell()函数;
在每行过滤结束时均会调用reset()函数.
总 结 本文在详细讲述HBase过滤器源码中各个函数作用的基础上, 结合一个具体的自定义过滤器案例分析了各个函数的执行流程. 化繁就简, 我们可以得出以下几点在过滤器实践中的经验:
自定义过滤器首先考虑继承FilterBase类;
相关的过滤逻辑主要在filterRowKey()和filterKeyValue()函数中, 可根据过滤器功能选择需要实现的函数;
在调试时, 可借助RegionServer的日志.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送