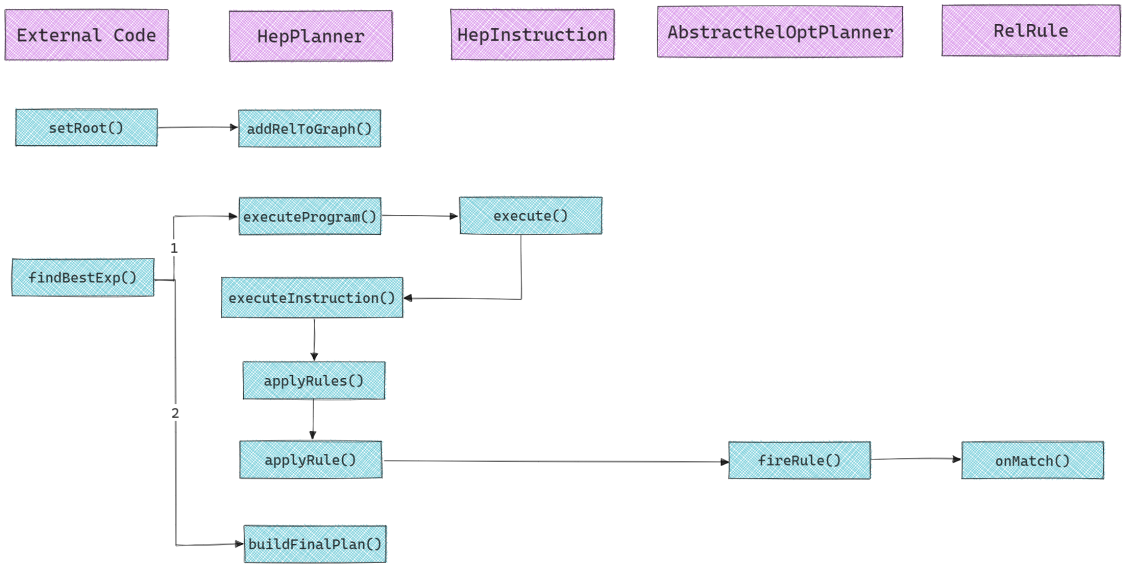
private HepRelVertex addRelToGraph(RelNode rel){ // Check if a transformation already produced a reference to an existing vertex. // 检查DAG顶点中是否已经包含了当前RelNode, 若包含证明该RelNode已经转换过, 直接返回即可 if (graph.vertexSet().contains(rel)) { return (HepRelVertex) rel; }
// Recursively add children, replacing this rel's inputs // with corresponding child vertices. // 递归将当前RelNode的子节点加入到DAG中 final List<RelNode> inputs = rel.getInputs(); // 原来的子节点 final List<RelNode> newInputs = new ArrayList<>(); // 转化为HepRelVertex之后的子节点 for (RelNode input1 : inputs) { // 递归将子节点加入到DAG中(深度优先遍历) HepRelVertex childVertex = addRelToGraph(input1); newInputs.add(childVertex); }
if (!Util.equalShallow(inputs, newInputs)) { RelNode oldRel = rel; rel = rel.copy(rel.getTraitSet(), newInputs); onCopy(oldRel, rel); } // Compute digest first time we add to DAG, // otherwise can't get equivVertex for common sub-expression // 计算RelNode的digest(唯一标识当前节点), 用于后续获取等价节点 rel.recomputeDigest();
// try to find equivalent rel only if DAG is allowed // 如果允许DAG, 尝试从已转化的顶点中获取等价HepRelVertex // 注意这里的noDag变量仅用于指示是否重用等价的表达式, // 与文中所说的由HepRelVertex组成的DAG无关 if (!noDag) { // Now, check if an equivalent vertex already exists in graph. HepRelVertex equivVertex = mapDigestToVertex.get(rel.getRelDigest()); if (equivVertex != null) { // Use existing vertex. // 如果已存在等价节点则直接返回 return equivVertex; } }
// No equivalence: create a new vertex to represent this rel. // 创建新的顶点并添加到DAG中 HepRelVertex newVertex = new HepRelVertex(rel); graph.addVertex(newVertex); updateVertex(newVertex, rel);
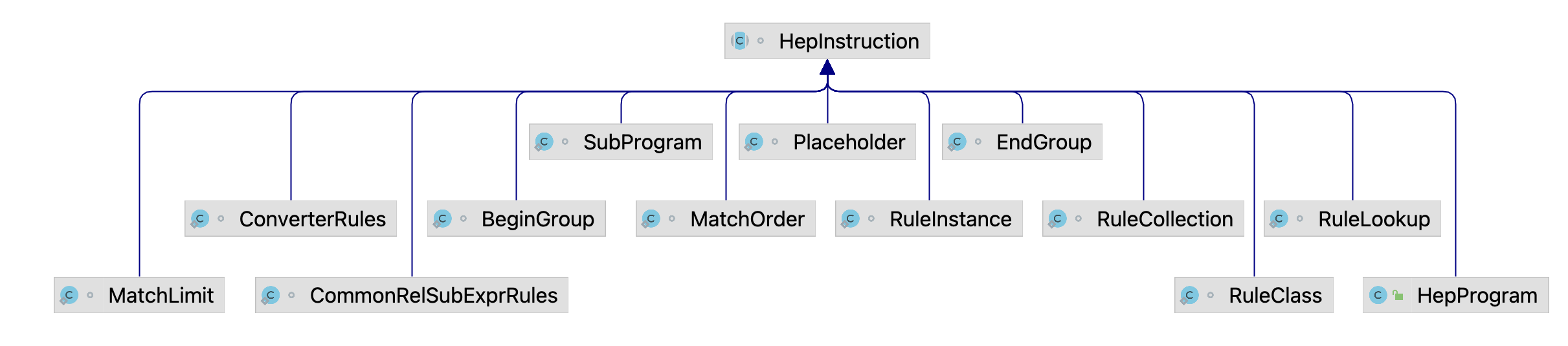
privatevoidexecuteProgram(HepProgram program){ HepProgram savedProgram = currentProgram; currentProgram = program; currentProgram.initialize(program == mainProgram); // 遍历当前HepProgram中的HepInstruction, 逐个执行 for (HepInstruction instruction : currentProgram.instructions) { instruction.execute(this); int delta = nTransformations - nTransformationsLastGC; if (delta > graphSizeLastGC) { // The number of transformations performed since the last // garbage collection is greater than the number of vertices in // the graph at that time. That means there should be a // reasonable amount of garbage to collect now. We do it this // way to amortize garbage collection cost over multiple // instructions, while keeping the highwater memory usage // proportional to the graph size. collectGarbage(); } } currentProgram = savedProgram; }
boolean fixedPoint; do { // 根据遍历顺序获取对应的迭代器 Iterator<HepRelVertex> iter = getGraphIterator(root); fixedPoint = true; while (iter.hasNext()) { // 遍历每个顶点 HepRelVertex vertex = iter.next(); for (RelOptRule rule : rules) { // 遍历每个RelOptRule // 对每个规则尝试进行匹配和转换 HepRelVertex newVertex = applyRule(rule, vertex, forceConversions); if (newVertex == null || newVertex == vertex) { continue; } ++nMatches; // 匹配次数超过最大次数, 则直接退出 if (nMatches >= currentProgram.matchLimit) { return; } if (fullRestartAfterTransformation) { // 当不是DEPTH_FIRST时, 匹配成功后从root节点重新开始, // 因为根节点可能因为转换而改变 iter = getGraphIterator(root); } else { // To the extent possible, pick up where we left // off; have to create a new iterator because old // one was invalidated by transformation. // 如果是DEPTH_FIRST, 那么直接递归匹配新节点的子节点. // 因为转换后的子节点可能被重新匹配到现有规则. iter = getGraphIterator(newVertex); if (currentProgram.matchOrder == HepMatchOrder.DEPTH_FIRST) { nMatches = depthFirstApply(iter, rules, forceConversions, nMatches); if (nMatches >= currentProgram.matchLimit) { return; } } // Remember to go around again since we're skipping some stuff. fixedPoint = false; } break; } } } while (!fixedPoint); }
private HepRelVertex applyRule(RelOptRule rule, HepRelVertex vertex, boolean forceConversions){ if (!graph.vertexSet().contains(vertex)) { returnnull; } RelTrait parentTrait = null; List<RelNode> parents = null; if (rule instanceof ConverterRule) { // Guaranteed converter rules require special casing to make sure // they only fire where actually needed, otherwise they tend to // fire to infinity and beyond. ConverterRule converterRule = (ConverterRule) rule; if (converterRule.isGuaranteed() || !forceConversions) { if (!doesConverterApply(converterRule, vertex)) { returnnull; } parentTrait = converterRule.getOutTrait(); } } elseif (rule instanceof CommonRelSubExprRule) { // Only fire CommonRelSubExprRules if the vertex is a common // subexpression. List<HepRelVertex> parentVertices = getVertexParents(vertex); if (parentVertices.size() < 2) { returnnull; } parents = new ArrayList<>(); for (HepRelVertex pVertex : parentVertices) { parents.add(pVertex.getCurrentRel()); } }
final List<RelNode> bindings = new ArrayList<>(); final Map<RelNode, List<RelNode>> nodeChildren = new HashMap<>(); // 判断当前节点子树的Pattern与规则指定的Pattern是否一致 boolean match = matchOperands(rule.getOperand(), vertex.getCurrentRel(), bindings, nodeChildren);
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送