本文已收录在合集Apche Calcite原理与实践中.
本文是Apache Calcite原理与实践系列的第七篇. 上一篇文章介绍了Calcite中的规则优化器HepPlanner, 本文将介绍成本优化器VolcanoPlanner. VolcanoPlanner是Volcano/Cascades风格的优化器, 支持基于成本的搜索, 并具有良好的扩展性. 本文首先介绍VolcanoPlanner中相关的概念和数据结构, 之后介绍现有的两种优化算法.
由于VolcanoPlanner的实现逻辑较为复杂, 包含了两种优化算法, 特别是Top-Down优化算法引入了较多的概念. 本文已经尽可能在厘清整体执行逻辑的基础上涵盖更多实现细节, 然而仍不可能面面俱到, 不过相信读者在理解了本文所讲述的内容之后, 可以轻松阅读源码理解本文未曾涉及的细节.
VolcanoPlanner概念和数据结构
RelSet和RelSubset
RelSet和RelSubset是VolcanoPlanner专用的数据结构, 由SQL得到的RelNode树需要转换为RelSet和RelSubset结构才能被VolcanoPlanner优化. RelSet是一组逻辑上等价的关系代数表达式集合, RelSubset(继承自AbstractRelNode)是一组逻辑上等价且物理属性相等的关系代数表达式集合. 一个RelSet中一般会包含多个逻辑上等价但物理属性不同的RelSubset. RelSet和RelSubset的核心成员如下.
1 | public class RelSubset extends AbstractRelNode { |
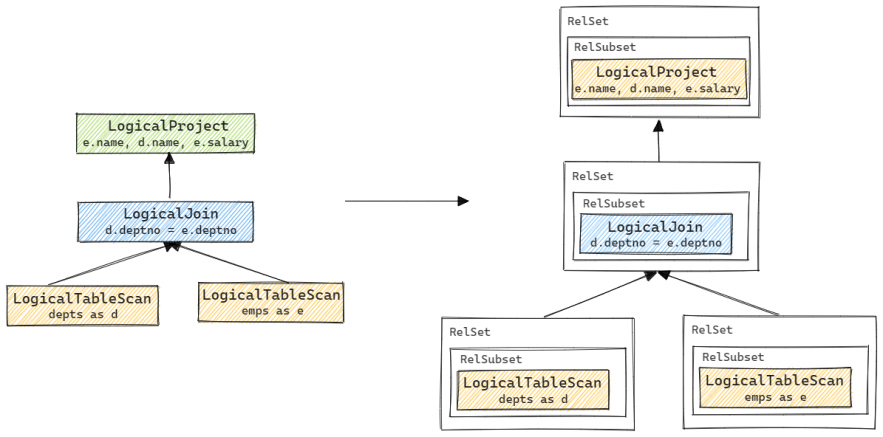
为了更好地理解RelNode树与RelSet和RelSubset结构的对应关系, 我们以一个具体的示例来进一步说明. 这里的示例表来自Calcite源码测试中常用的HrClusteredSchema, 其SQL语句对应的RelNode树及转换后的RelSet和RelSubset结构如下图所示. 图中出现的AbstractConverter会在下一小节进一步介绍, 这里可暂时忽略.
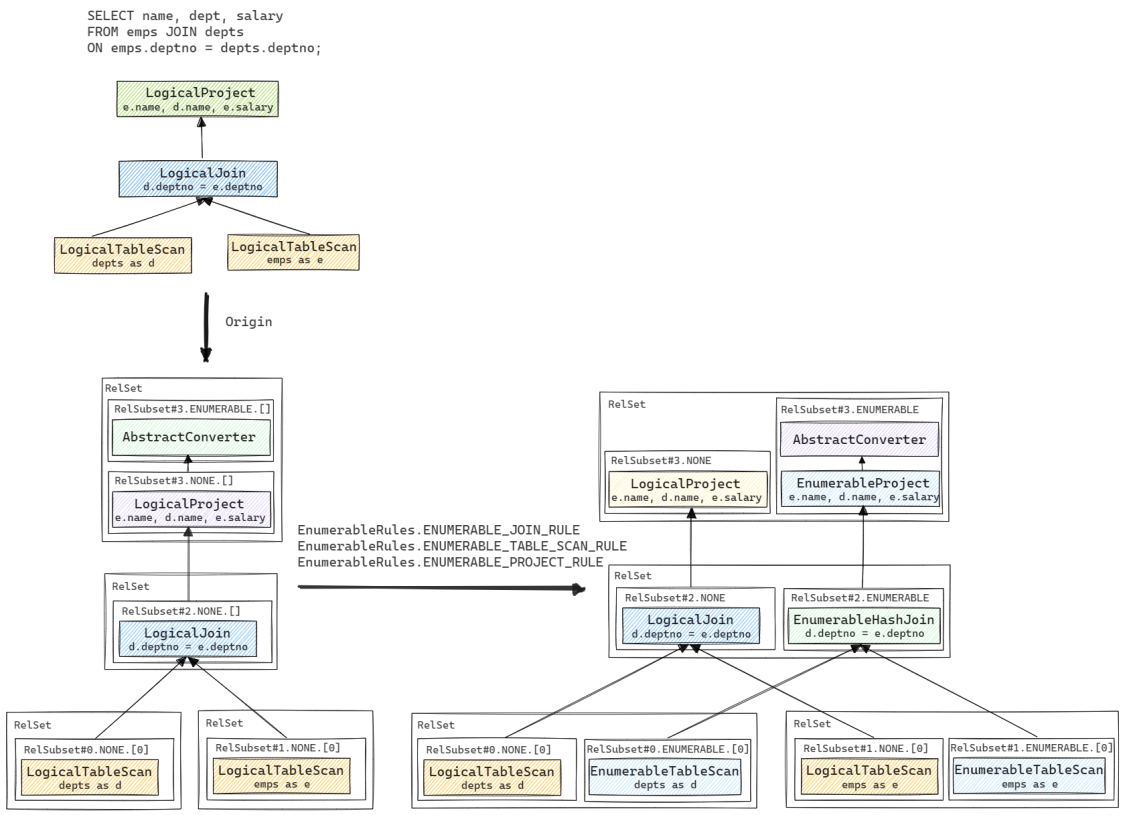
RelNode树会首先被转化为对应的RelSet和RelSubset结构. 之后在优化过程中, 会根据给定的Convention和规则产生更多等价的RelSet和RelSubset, 如上图最右侧所示. 最终在其中选出代价最低的节点组成执行计划, 具体流程下文会进一步讲述.
AbstractConverter
AbstractConverter是一种特殊的节点, 用于对节点的物理属性进行转换, 它也是一种RelNode类型, 其继承关系如下图所示.

VolcanoPlanner最终生成的是物理执行计划, 因此在优化过程中需要考虑各个节点的物理属性, 子节点的物理属性必须满足父节点的输入需要, 例如对于Merge Join而言, 输入的左右表必须按Join Key排序, 否则就需要在不满足排序属性的表之上增加一个排序算子. 为了实现这一点, 目前在Calcite中有两种方法:
- 在基于迭代的优化算法中, 如果子节点的物理属性不满足父节点输入需要, 便会在中间添加一个新的
AbstractConverter, 它会跟ExpandConversionRule相匹配, 这样在后续规则应用阶段会触发该规则, 并调用RelTraitDef.convert()将子节点的物理属性进行转换以满足父节点输入需求. - 在Top-Down优化算法中, 除根节点外, 父节点的物理属性可通过
passThroughTraits()方法传递给子节点, 这样在子节点优化过程中产生的物理算子的物理属性如果不满足父节点需求, 便会调用对应Convention的enforce()方法进行物理属性的转换, 而不需要添加AbstractConverter.
同样, 为了更好地说明AbstractConverter到底是如何使用的, 我们还是用一个具体的例子来一探究竟. 这个例子十分简单, 对应的SQL语句是SELECT * FROM emps, 翻译成关系算子就是一个LogicalTableScan算子. 我们分几种情况来看AbstractConverter是如何起作用的:
- 当物理计划仅需满足
EnumerableConvention.INSTANCE这一物理属性时, 在准备阶段会在RelSet中添加一个AbstractConverter(其traitSet属性为[EnumerableConvention]), 它是由VolcanoPlanner.ensureRootConverters()添加的, 用于保证根节点能转换到所需的物理属性. 不过在这个例子中, 所添加的AbstractConverter其实没有起到任何作用, 因为ConventionTraitDef.convert()只会对isGuaranteed()方法返回true的ConverterRule起作用, 而转换到EnumerableRel的ConverterRule其isGuaranteed()方法固定返回false.Convention这一物理属性的转换(即从LogicalTableScan到EnumerableTableScan的转换)实际是由注册到VolcanoPlanner的ConverterRule(即EnumerableRules.ENUMERABLE_TABLE_SCAN_RULE)来实现的. - 现在我们来看一种稍微复杂一点的情况, 假设我们需要输出数据按第1列(从0开始计数)排序, 这样整个物理计划的根节点的物理属性就变成了
[EnumerableConvention.INSTANCE, RelCollations.of(1)]. 此时由于由两个物理属性需要转换, 在准备阶段VolcanoPlanner.ensureRootConverters()就不会添加任何AbstractConverter(原因下文会进一步解释). 在优化阶段, 两种优化算法会有不同的行为:- 对于迭代算法, 在生成
EnumerableTableScan后注册该节点时, 会发现该节点无法满足RelCollationImpl [1]这一物理属性, 因此在调用RelSet.add()向RelSet添加该节点时会触发RelSet.getOrCreateSubset()->RelSet.addConverters()添加一个AbstractConverter, 后续在规则应用阶段展开ExpandConversionRule时会生成一个LogicalSort进行排序. - 对于Top-Down算法, 由于
enforce()代替了AbstractConverter的工作, 因此也就不需要再添加AbstractConverter节点了.
- 对于迭代算法, 在生成
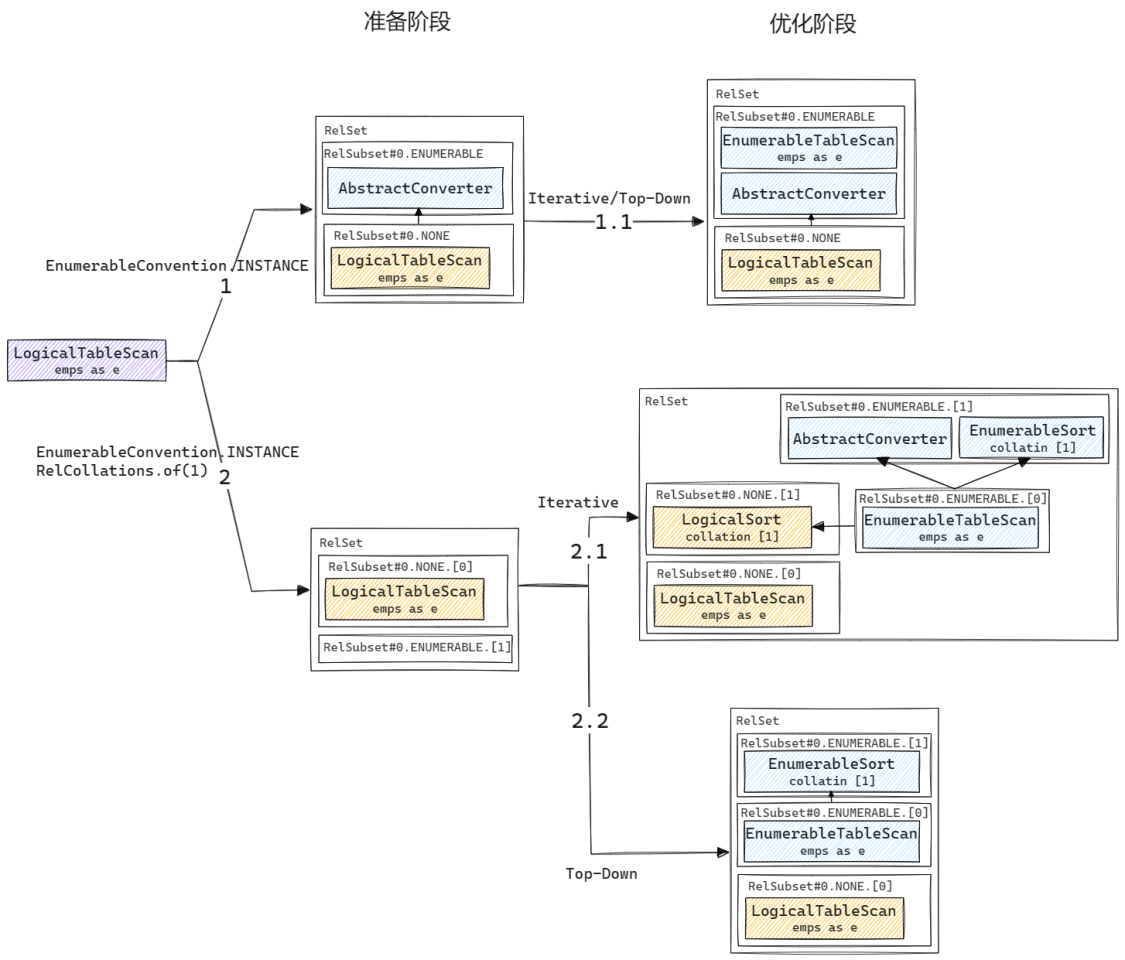
从上述例子中, 读者可能会对几个细节有所疑问:
- 为什么情况1中, 准备阶段在根节点所在
RelSet中添加了一个AbstractConverter, 而情况2中没有. 这跟ensureRootConverters()的执行逻辑有关, 它只在所需物理属性与根节点物理属性仅有一个不同时才会在根节点之上添加一个AbstractConverter.ensureRootConverters()的进一步解析可参考附录二. - 可以看到在情况1中虽然添加了一个
AbstractConverter来保证根节点的Convention属性转换, 但实际上这里的AbstractConverter并没有起作用. 在Calcite的代码中,Convention之间的转换都是通过ConverterRule来实现的. 而ConventionTraitDef.convert()是用来做多个Convention的连续转换的, 例如希望从A->C, 并且已经有了A->B, B->C两个ConverterRule, 且其isGuaranteed()方法返回true, 那么就可通过最短路径直接进行连续转换, 这在Apache Drill等框架中可能用到.
总结来说, 在以下几种情况下会添加AbstractConverter:
- 在准备阶段, 或者在优化阶段发生根节点合并的情况(见附录二), 会调用
ensureRootConverters()尝试添加AbstractConverter; - 在迭代优化算法中, 如何新产生节点的物理属性不符合父节点要求, 那么会添加一个
AbstractConverter来进行物理属性的转换.
Cost Model
在Calcite中, 一个算子的物理执行成本由RelOptCost描述, VolcanoPlanner中默认使用的是VolcanoCost, 包含算子执行的CPU, IO成本以及中间结果的行数. 在分布式系统中, 算子执行的成本通常还包括数据在不同机器间的传输成本, 即网络成本. 对于这种情况可以继承RelOptCost实现一个新的成本模型, 并创建一个继承于RelOptCostFactory的工厂类用于构造自定义成本, 在构造VolcanoPlanner时传入该工厂类即可.

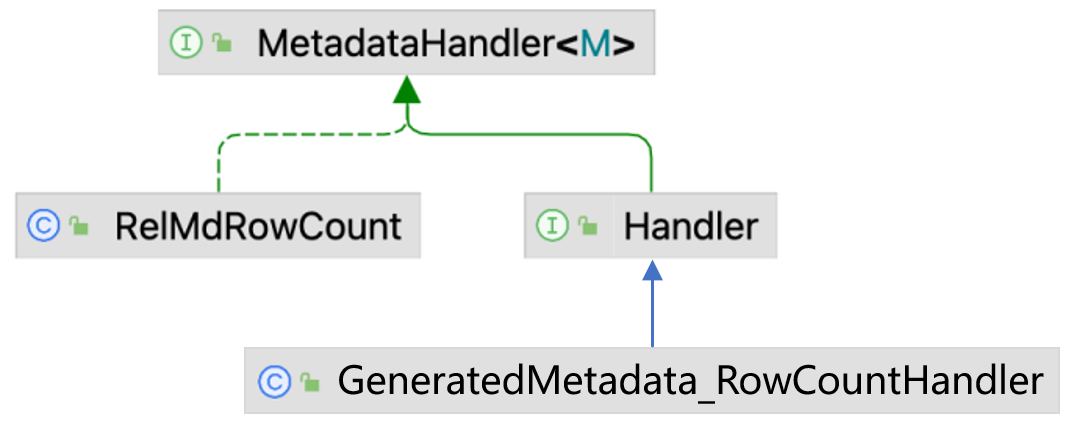
RelOptCost的计算需要借助各种统计值, 如表的行数, 谓词的Selectivity等. 在Calcite中这种统计值都由Metadata表示, 下图列举了几种常见的类型, 完整的统计值类型都在BuiltInMetadata中. Metadata接口的子类型都是接口, 实际获取或计算统计值的逻辑都在Handler中, 它继承于MetadataHandler, 每个Metadata中都有一个Handler.

MetadataHandler有两种实现:
- 一种是可用于计算具体的
RelNode算子统计值的实现, 例如用于获取行数的RelMdRowCount, 具有计算各种类型RelNode算子行数的实现, 如:Double getRowCount(Union rel, RelMetadataQuery mq)Double getRowCount(Filter rel, RelMetadataQuery mq)
- 一种是各个
Metadata子接口中的Handler接口,Handler接口中只有一个用于获取RelNode算子对应统计值的方法, 例如RowCount中的方法为:Double getRowCount(RelNode r, RelMetadataQuery mq).Handler是供RelMetadataQuery调用的接口, 它的实现类是动态生成的, 例如RowCount.Handler对应的生成类是GeneratedMetadata_RowCountHandler, 代码可见附录一, 其核心逻辑就是将传入的RelNode转化为具体的实现类型, 并调用RelMdRowCount中对应的方法.
由于MetadataHandler的具体实现较多, Calcite又提供了RelMetadataProvider来对MetadataHandler进行统一的创建和管理. 其实现类如下图所示, 其中:
ReflectiveRelMetadataProvider用于辅助创建具体的RelMetadataProvider, 例如用于创建RelMdRowCount类型的RelMetadataProvider.DefaultRelMetadataProvider包含由ReflectiveRelMetadataProvider创建的RelMetadataProvider集合.JaninoRelMetadataProvider会在DefaultRelMetadataProvider的基础上, 通过动态代码生成来创建用于创建Handler实现类的RelMetadataProvider.

RelMetadataQuery继承自RelMetadataQueryBase, 是Calcite中的的关系算子元数据查询接口标准, VolcanoPlanner是调用RelMetadataQuery中的方法进行成本计算的. RelMetadataQuery的创建在RelOptCluster中, 其核心代码如下, 可以看到RelMetadataQuery中包含的实际是JaninoRelMetadataProvider, 其中又持有DefaultRelMetadataProvider, 在RelMetadataQuery的具体方法中会调用JaninoRelMetadataProvider的方法动态生成一个Handler.
1 | public class RelOptCluster { |
关于元数据获取这部分的实现逻辑比较绕, 既用到了反射, 又用到了动态代码生成. 之所以实现地这么复杂, 我认为有两个原因:
- 一是不希望手写
if-else去为每个RelNode的实现类找到对应的计算统计值的方法. - 二是为了有更好的扩展性, 成本计算中的统计值有比较强的扩展需求, 基于现在这套实现可以方便地进行扩展, 而不用修改现有代码.
有了上面的铺垫, 我们再来看下VolcanoPlanner中的成本计算过程, 其整体流程如下:
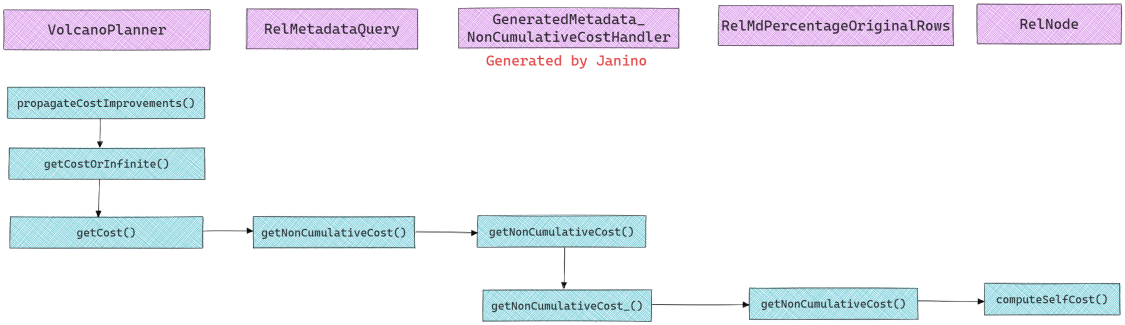
- 在VolcanoPlanner的
propagateCostImprovements()中会触发成本计算,getCost()会递归调用RelMetadataQuery.getNonCumulativeCost()计算当前节点及其子节点的成本. RelMetadataQuery.getNonCumulativeCost()会计算当前节点的成本, 它会调用动态生成的类GeneratedMetadata_NonCumulativeCostHandler(具体代码见附录一)中的getNonCumulativeCost().GeneratedMetadata_NonCumulativeCostHandler调用的是RelMdPercentageOriginalRows.getNonCumulativeCost(), 最终会调用RelNode.computeSelfCost()计算成本.RelNode的实现类有不同的computeSelfCost()实现, 例如TableScan会调用底层RelOptTable来获取行数,Calc会通过RelMetadataQuery.getRowCount()来获取行数.
RuleDriver
VolcanoPlanner支持不同的优化算法, RuleDriver是不同优化算法的抽象接口, 目前有两种实现, 其中:
IterativeRuleDriver是基于迭代的优化算法;TopDownRuleDriver是Top-Down优化算法, 是目前State of the art的关系代数优化算法.

在RuleDriver内部, 由RuleQueue管理已经注册的规则.

VolcanoPlanner优化流程
VolcanoPlanner的优化流程较为复杂, 我们先来看看VolcanoPlanner中的核心成员, 理解这些核心成员中所存储的内容及其变化过程可帮助我们更好地理解VolcanoPlanner的优化过程.
1 | public class VolcanoPlanner extends AbstractRelOptPlanner { |
VolcanoPlanner中存在两种优化算法, 分别是基于迭代的优化算法和Cascades风格的Top-Down优化算法. 这两种优化算法的准备工作都是相同的, 下面我们先介绍几个准备流程, 之后分别介绍两种优化算法的执行流程.
准备流程
准备流程相当于数据结构的初始化, 后续的算法都是在准备阶段产出的数据结构上进行的. 我们可以从RuleSetProgram中看到使用VolcanoPlanner的步骤.
1 | /** Program backed by a {@link RuleSet}. */ |
注册优化规则
Calcite中无论是HepPlanner还是VolcanoPlanner, 在优化过程中都使用了规则. 不同之处在于, HepPlanner只是”无脑”按一定的顺序不断遍历整个RelNode树, 一旦发现某个子树节点符合规则所定义的Pattern就对其进行转换, 直到RelNode树在给定的规则集下不再发生变化或遍历次数达到上限; 而VolcanoPlanner的目标是搜索成本最小的计划, 它可以在多个不同的子计划中选出代价最小的, 更重要的是它可以支持生成指定Calling Convention的执行计划.
因此, 使用VolcanoPlanner的第一步也是挑选并添加所需规则. 这一步的实现在VolcanoPlanner中的addRule()方法中, 其代码如下.
1 | public boolean addRule(RelOptRule rule) { |
上述代码中需要注意的是, 如果在调用addRule()之前还没有调用过setRoot(), 那么在classes中并没有记录, 因此addRule()中并不会向classOperands添加记录. 后续在注册RelNode树时会向classOperands中添加RelNode匹配的规则Pattern.
注册RelNode
在VolcanoPlanner中, 其优化过程是基于RelSet和RelSubset展开的, 因此在优化前需要将待优化的RelNode树转化为RelSet和RelSubset形式的表达. 以下是在准备阶段, RelNode树注册为RelSet和RelSubset的案例.
除了在准备阶段会将整棵待优化的RelNode树进行注册, 后续如果有规则触发后产生了新的RelNode类型, 也会进行注册. RelNode注册的主要实现逻辑在registerImpl()函数中, 其核心流程如下图所示.

RelNode注册过程中的几个要点是:
RelNode.onRegister()会为当前节点的每个子节点调用VolcanoPlanner.ensureRegistered()进行注册.registerClass()会将当前节点的类型加入classes中, 并调用onNewClass()从已经注册的规则中找到与当前节点匹配的规则, 并将其Pattern记录到classOperands中.addRelToSet()会为当前的RelNode创建一个对应的RelSubset(如果没有RelTrait相同的RelSubset的话), 或将当前的RelNode加入到已有的RelSubset中(如果已有RelTrait相同的RelSubset). 同时还会调用propagateCostImprovements()计算当前节点的Cost, 并将其传播给父节点.fileRules()会根据classOperands中注册的规则Pattern, 找到与当前节点匹配的规则, 并将其放入规则队列中, 后续算法会根据这一队列进行优化.
总结来说, 注册RelNode这个过程是准备阶段的核心, 在这一过程中, 会将与原始的待优化RelNode树匹配的规则放入相应的队列中. 后续的算法, 无论是基于迭代还是Top-Down优化算法都是基于队列中的规则展开的.
需要说明的是registerImpl()是一个私有方法, 注册RelNode的过程并不需要用户显式调用. 在设置目标RelTrait和设置根节点时, 都会间接调用registerImpl()注册RelNode, 下文会进一步介绍.
设置目标RelTrait
由于VolcanoPlanner生成的是物理计划, 因此需要设置目标输出计划的物理属性, 一般来说Convention属性是必须要设置的, 在Calcite中如果要生成执行计划, 可将Convention设置为EnumerableConvention或BindableConvention.
一般地, 在使用VolcanoPlanner时只需为根节点调用changeTraits()即可. changeTraits()的实现逻辑比较简单, 首先调用ensureRegistered()确保当前节点已经注册, 最后根据需要的属性, 返回已有的RelSubset或创建一个新的RelSubset.
1 | @Override public RelNode changeTraits(final RelNode rel, RelTraitSet toTraits) { |
设置根节点
在执行优化前的最后一步就是调用setRoot()设置根节点. 其实现逻辑也很简单, 首先会调用registerImpl()确保根节点已经注册; 其次由于根节点没有父节点, 因此会调用ensureRootConverters()尝试添加AbstractConverter用于保证输出的物理属性符合要求.
1 | @Override public void setRoot(RelNode rel) { |
优化算法
在准备工作完成后, 即可调用findBestExp()执行优化算法, 搜索代价最小的执行计划. VolcanoPlanner中提供了两种优化算法, 默认使用的是基于迭代的优化算法, 可以调用VolcanoPlanner.setTopDownOpt(true)启用Top-Down优化算法.
基于迭代的优化算法
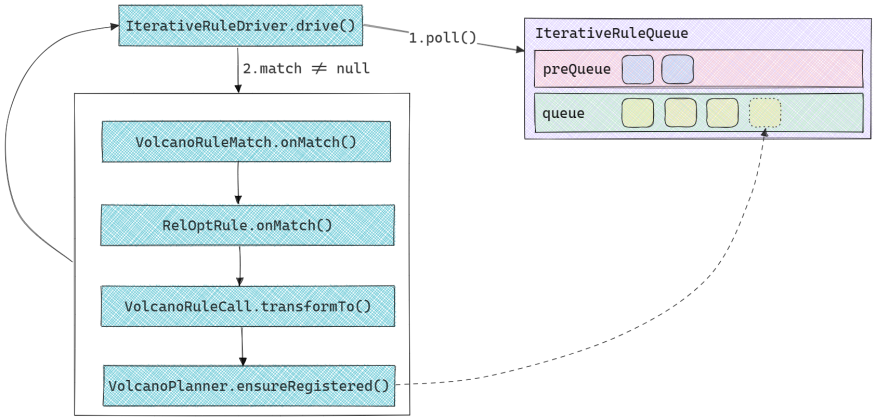
基于迭代的优化算法实现比较简单, 所有与当前RelNode树及其子树匹配的规则都已经在准备阶段被放入了IterativeRuleQueue. 在优化阶段, 不断从队列中取出一个规则用于执行, 直到队列为空. 整体执行流程如下图所示:
IterativeRuleQueue有两个队列,preQueue用于存放SubstitutionRule(即应用后一定能产生正向收益的规则, 如CalcRemoveRule,ProjectJoinRemoveRule等),queue用于存放其他规则. 在算法执行时会优先弹出preQueue中的规则.- 在规则执行完成之后, 会调用
VolcanoPlanner.ensureRegistered()注册规则产生的新节点, 在此过程中如果发现新节点与某个注册规则匹配, 即将匹配的规则再次加入到IterativeRuleQueue中.
为了更好地理解上述过程, 我们以一个具体的例子来进一步说明. 还是使用前文中双表Join的案例, 不过这里把输入的优化规则做了一些改动, 把原来的EnumerableRules.ENUMERABLE_JOIN_RULE改成了EnumerableRules.ENUMERABLE_MERGE_JOIN_RULE, 这样Join的物理算子就会从EnumerableHashJoin变成EnumerableMergeJoin. 整个优化过程就是不断从队列中取出规则并应用, 这些规则大部分是ConverterRule, 应用之后会产生一个物理算子. 唯一不同的是EnumerableMergeJoinRule, 它产生的算子EnumerableMergeJoin需要输入节点按Join Key排序, 因此需要添加一个AbstractConverter, 及与之匹配的ExpandConversionRule, 之后该规则触发时便会添加一个LogicalSort来满足排序属性. 读者可调试运行IterativeMergeJoinExample以获得更直观的感受.

Top-Down优化算法
Top-Down优化算法借鉴于Columbia的实现, 其本质上是一种自顶向下的记忆化动态规划算法, 由于递归解法效率低下, 因此Columbia定义了多种Task, 并利用栈消除递归, 优化的整体过程就是不断从栈顶取出需要执行的Task(在Task中可能生成新的Task放入栈中), 直到栈为空.
概念及数据结构
Columbia衍生自Volcano/Cascades, 我们先介绍一下Calcite中与之对应的概念和具体实现.
| Volcano/Cascades概念 | Calcite VolcanoPlanner实现 |
| Operator(Logical/Physical) | RelNode(没有LogicalRelNode基类, 但仍可区分Logical/Physical) |
| Rule(Transformation/Implementation) | RelOptRule(TransformationRule/ConverterRule) |
| Enforcer rule | ConverterRule |
| Group(逻辑等价类) | RelSet |
| RelSubset | |
| Pattern | 通过RelOptRuleOperand来实现 |
| Property(Logical/Physical) | RelTrait |
Calcite中Task的定义也基本可与Columbia对应, 为了方便实现做了一些轻微调整.
| Columbia | Calcite |
| O_GROUP | OptimizeGroup |
| O_INPUTS | OptimizeInputs OptimizeInput1 |
| O_EXPR | OptimizeMExpr |
| E_GROUP | ExploreInput |
| APPLY_RULE | ApplyRules |
OptimizeGroup用于优化RelSubset. 它会先优化当前RelSubset所属的RelSet中的物理节点(这一过程为Implement), 即生成OptimizeInputs/OptimizeInput1; 之后会优化所属RelSet中的逻辑节点(这一过程为Explore), 即生成OptimizeMExpr. 这里先优化物理节点是为了可以快速获得一个Upper Bound以便进行剪枝.
OptimizeInputs/OptimizeInput1会为每个子节点创建OptimizeGroup, 并生成CheckInput为子节点设置优化后的成本. OptimizeInput1是在只有一个输入节点情况下的简化版本.
OptimizeMExpr用于优化逻辑节点, 它会先Explore每个子节点, 即生成ExploreInput; 然后为当前节点应用规则, 即生成ApplyRules.
ExploreInput为当前RelSubset中的每个逻辑节点生成OptimizeMExpr.
ApplyRules会为当前节点找到所有的VolcanoRuleMatch(在Explore节点仅会应用TransformationRule), 并为每个VolcanoRuleMatch生成一个ApplyRule. ApplyRule会真正应用一个规则, 如果在规则应用过程中生成了新的节点, 会调用VolcanoPlanner.addRelToSet()加入RelSubset, 同时会触发TopDownRuleDriver.onProduce(), 其流程与OptimizeGroup类似, 对于物理节点会生成OptimizeInputs/OptimizeInput1, 而对于逻辑节点会生成OptimizeMExpr.
Task执行流程
各个Task之间的调用关系如下图所示, 其中蓝色阴影框中是Columbia中定义的Task, 主要的优化流程都在这些Task中, 其他框是Calcite实现的Task, 用于执行一些辅助工作. 另外, 图中的红色箭头表示进入到下一层节点.
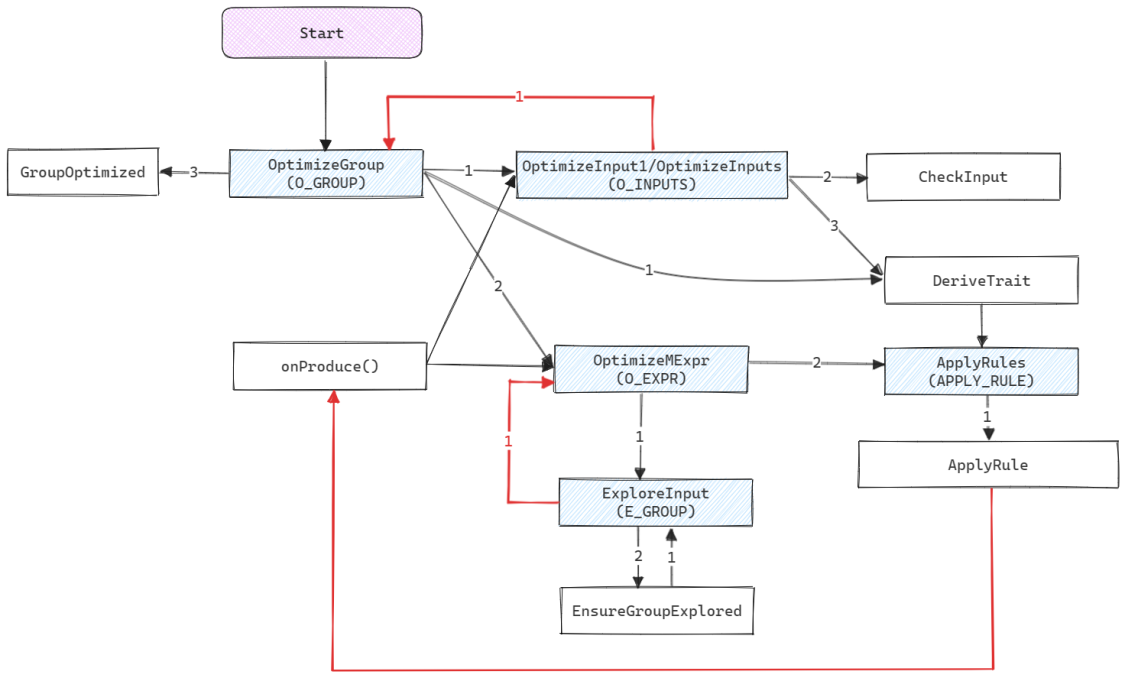
可以看到整个调用流程还是比较复杂的, 我们可以从几个闭环来厘清整体思路:
- 从
OptimizeGroup到OptimizeInputs/OptimizeInput1这个环是整个Implement的过程, 它会不断递归直到已经优化过的节点或叶节点. 对于已经优化过的节点或者叶节点, 则会进入另一个环. - 从
OptimizeMExpr到ExploreInput这个环是整个Explore过程, 它也会不断递归, 对整个子树应用匹配的规则. 这里需要注意的一点是, 如果OptimizeMExpr是OptimizeGroup生成的, 那么属于Implement过程, 在此过程中会应用所有匹配的规则; 如果OptimizeMExpr是ExploreInput生成的, 那么属于Explore过程, 在此过程中仅仅会优化逻辑节点, 也就是仅会应用TransformationRule.
剪枝的实现
目前, Calcite的实现仅支持对物理节点进行剪枝, 而Columbia对于逻辑节点会根据逻辑属性计算一个Lower Bound. 剪枝的过程主要实现在OptimizeInputs中:
- 对于
bestCost不为无限大的RelSubset(即物理节点), 首先根据Upper Bound(在OptimizeGroup时传入)计算其输入节点的Upper Bound之和upperForInput, 再调用RelMetadataQuery计算所有输入节点的Lower Bound之和lowerBoundSum, 如果lowerBoundSum > upperForInput则可以不再优化当前节点的子节点, 直接跳过. OptimizeInputs优化完一个节点后,CheckInput会用实际的成本替代之前的Lower Bound.
为了更形象地描述剪枝的过程, 我们举一个具体的例子, 读者可运行PruningJoinExample观察更多细节. 还是上文的表达式, 在优化rel#21:RelSubset#4.ENUMERABLE.[]这个Group时:
- 已知的最优成本是
{17.34517744447956 rows, 9.0 cpu, 0.0 io}(即整个Group的Upper Bound), 这个最优成本来自于rel#26:EnumerableHashJoin.ENUMERABLE.[0](RelSubset#24,RelSubset#25). - 在优化
rel#33:EnumerableMergeJoin.ENUMERABLE.[[1], [5]](RelSubset#31,RelSubset#25)这个节点时, 由于其本身的成本为{8.8 rows, 0.0 cpu, 0.0 io}. 因此对于该节点而言, 其upperForInput为{8.54517744447956 rows, 9.0 cpu, 0.0 io}, 而此时它的两个子节点的成本(Lower Bound)rel#31:RelSubset#1.ENUMERABLE.[1]为{8.0 rows, 182.445678223346 cpu, 0.0 io},rel#25:RelSubset#0.ENUMERABLE.[0]为{3.0 rows, 4.0 cpu, 0.0 io}, 其和大于upperForInput, 因此rel#33:EnumerableMergeJoin.ENUMERABLE.[[1]可以直接被剪枝.

物理属性的Pass-through和Derive
由于VolcanoPlanner输出的是优化后的物理表达式, 因此在优化过程中必须考虑节点的物理属性. 在基于迭代的优化算法中, 父子节点之间无法传递物理属性, 因此如果父子节点之间的物理属性不匹配, 便会在其中放置一个AbstractConvertor, 之后在优化中会应用与之匹配的规则ExpandConversionRule来调用RelTraitDef.convert()实现转换. 在Top-Down优化算法中, 父子节点之间可以传递物理属性, 将父节点的物理属性传递给子节点称为Pass-through, 而将子节点的物理属性汇集到父节点称为Derive.
Pass-through和Derive的实现接口都在PhysicalNode中, 因为只有物理节点才需要关心物理属性.
- 对于Pass-through可以按需实现
passThrough(RelTraitSet)或passThroughTraits(RelTraitSet). 注意这两个函数的返回类型不同, 供外部调用的是前者, 而用户一般只需要实现passThroughTraits(RelTraitSet)即可. - 由于一个节点可能有多个子节点, 在Derive时可能存在多种模式, 如
LEFT_FIRST(表示在某个物理属性冲突时以最左侧的子节点为准),RIGHT_FIRST,BOTH和OMAKASE(表示由用户自行决定如何处理各个子节点中冲突的物理属性), 这些模式都定义在DeriveMode中. 在OMAKASE模式下需要实现derive(List), 否则可实现derive(RelTraitSet, int)或deriveTraits(RelTraitSet, int), 一般情况下只需实现后者即可.
1 | public interface PhysicalNode extends RelNode { |
Pass-through
为了更好地理解Pass-through的原理, 我们先以两个具体的例子来说明物理节点该如何实现Pass-through. 之后再介绍在优化过程中是如何触发物理属性的Pass-through的.
对于像Project, Filter这类简单算子, 一般对于不同的物理属性没有什么不同的处理逻辑, 因此在Pass-through的时候直接传递父节点的物理属性即可. 以EnumerableFilter为例, 其passThroughTraits()实现如下, 仅仅是接收了来自父节点的RelCollation.
1 | @Override |
对于像Join这样的算子, 就需要一些额外的处理了. 以EnumerableHashJoin为例, 由于其结果不会改变Probe side的顺序, 因此如果所需的顺序恰好是Probe side的顺序, 那么可以直接将其穿透到Probe side节点. 其代码实现如下, 仅当Join类型是Inner或Left join, 且排序键在左侧节点时才穿透排序属性.
1 | static @Nullable Pair<RelTraitSet, List<RelTraitSet>> passThroughTraitsForJoin( |
在整个优化过程中, 有两个地方会触发Pass-through:
- 一个是在
getOptimizeInputTask()生成OptimizeInputs/OptimizeInput1时, 如果节点与所在的RelSubset的物理属性不匹配, 会调用TopDownRuleDriver.convert()进行转换, 其中便会触发Pass-through. - 另一个是在新节点生成时, 会调用
TopDownRuleDriver.onProduce(), 如果是物理节点也会调用getOptimizeInputTask()触发Pass-through.
Derive
对于像Project, Filter这类简单算子, 其Derive过程同样比较简单, 直接从子节点收集物理属性向上传递即可, 这里不再赘述. 而对于EnumerableHashJoin算子, 由于Join之后只会保留Probe side的顺序, 因此只会向上传递Probe side的排序属性.
在每个OptimizeInputs/OptimizeInput1完成后都会生成一个DeriveTrait任务, 它会调用TopDownRuleDriver.derive()进行物理属性的Derive.
结束流程
经过上述优化之后, 正常情况下相应的RelSubset都产生了一个成本最低的物理表达式. 结束流程就是从根节点开始进行一次深度优先遍历, 将整个执行计划还原为RelNode(非RelSubset)结构.
总结
本文详细介绍了Calcite中的成本优化器VolcanoPlanner, 在1.24之后的版本中已经支持Cascades风格的Top-Down优化算法. 可以看到VolcanoPlanner的优化过程是比较复杂的, 引入了不少新的概念, 涉及诸多细节处理, 代码实现上也比较绕, 在阅读源码时可以先从具体案例(例如本文给出的几个可运行示例)出发, 多运行调试, 把握处理要点, 切勿太早陷入过多细节. 以笔者的经验来看, 很多细节只能反复调试才能理解其原理, 遇到难以理解到的逻辑可从宏观角度出发, 反推在什么样的结构中才有可能遇到这种情况, 然后构造一个表达式调试观察其优化过程.
参考
[1] Custom traits in Apache Calcite
[2] What is Cost-based Optimization?
[3] Memoization in Cost-based Optimizers
[4] Metadata Management in Apache Calcite
[5] Efficiency in the Columbia Database Query Optimizer
[4] Calcite中新增的Top-down优化器
[5] SQL查询优化原理与Volcano Optimizer介绍
[6] 揭秘TiDB新优化器: Cascades Planner原理解析
附录
附录一: 代码生成
Calcite生成的NonCumulativeCost.Handler实现类.
1 | package org.apache.calcite.rel.metadata.janino; |
Calcite生成的NonCumulativeCost.Handler实现类.
1 | package org.apache.calcite.rel.metadata.janino; |
Calcite生成的LowerBoundCost.Handler实现类.
1 | package org.apache.calcite.rel.metadata.janino; |
附录二: ensureRootConverters()解析
ensureRootConverters()会在两个地方被调用:
- 一是在优化开始前, 在
VolcanoPlanner.setRoot()和VolcanoPlanner.findBestExp()中调用, 这里虽然调用了两次, 实际第二次只是确认, 没有产生实际效果. - 二是在优化过程中, 如果如果出现了和根节点所在
RelSet等价的其他RelSet, 那么两个RelSet就会进行合并, 此时必然涉及到根节点的变动, 因此这时也需要再调用一次nsureRootConverters(). 为了更好地理解这一过程, 笔者提供了一个可运行的案例RelSetMergeExample, 读者可运行调试.
下面我们看下ensureRootConverters()的实现代码.
1 | /** Ensures that the subset that is the root relational expression contains |
这里再进一步解释一下为什么只有在1个RelTrait不同时才会添加AbstractConverter. 其实我们看一下AbstractConverter是如何应用的就明白了, 在ExpandConversionRule中实际是通过VolcanoPlanner.changeTraitsUsingConverters()来实现物理属性转换的, 而它最终返回的只有一个值, 就是最后一个属性转换后对应的节点. 如果根节点需要转换多种物理属性, 可以多次调用VolcanoPlanner进行多重转换.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送