本文已收录在合集Apche Calcite原理与实践中.
本文是Apache Calcite原理与实践系列的第三篇, 上一篇文章介绍了Calcite解析器的实现原理, 本文将介绍如何对解析器输出的SQL解析树进行语义分析, 如表名, 字段名, 函数名和数据类型的检查. 相对于解析器, SQL验证部分的内容扩展需求较少, 所以本文重点介绍Calcite中Schema相关的接口(用于提供元数据), 以及SQL验证相关的概念, 最后以SELECT语句为例, 介绍验证过程中的重要步骤.
Calcite元数据接口
SQL解析阶段只要SQL语句中没有语法错误便可解析成功, 而不会关注SQL语句的具体语义是否正确, 比如表是否存在, 字段是否存在等. SQL验证阶段就会检查SQL语句的语义是否正确, 这就需要依赖于外部提供的元数据信息. 为此, Calcite提供了一系列用于提供元数据信息的接口. 这里我们将第一篇文章中与SQL验证相关的部分复制过来, 以便对照讲述.
1 | // 创建Schema, 一个Schema中包含多个表. Calcite中的Schema类似于RDBMS中的Database |
从上述代码中可以看到, 有三个与元数据信息有关的重要接口: Schema(SimpleSchema继承自Schema), CalciteSchema和CatalogReader. 下面我们将分别介绍.
Schema是用于描述数据库结构(如包含哪些表, 函数等)的一个接口. 在关系型数据库管理系统中通常有Catalog, Schema, Table这样的层级结构来管理表和数据库, 不过并非每种RDBMS都完全这么实现, 比如MySQL不支持Catalog, 并且用Database来替代Schema的位置. Calcite的Schema接口可以表示Catalog或Schema, 因为Schema接口支持嵌套, 这样就可以用来表示Schema嵌套在Catalog里这种层级结构. Schema接口的实现类如下图所示.
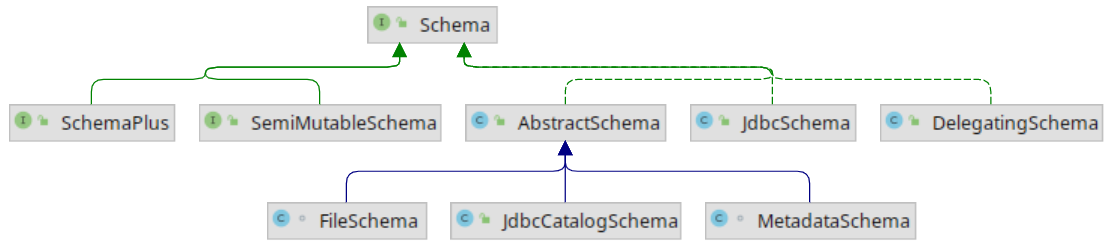
这里介绍几个重要的实现类:
SchemaPlus接口是Schema接口的扩展, 增加了一些新的方法, 比如添加表.SchemaPlus不应该由用户创建.AbstractSchema是一个默认实现, 我们代码中的SimpleSchema就继承自该类.DelegatingSchema是一个简单的代理类, 将所有的操作交给内部的一个Schema实现.
CalciteSchema接口是Schema接口的包装类, 可以嵌套多个Schema实体, 并提供了一些工具方法, 比如plus()方法可以将内部Schema包装为SchemaPlus后返回. 它有两个实现类, 在我们的代码中使用的是SimpleCalciteSchema.
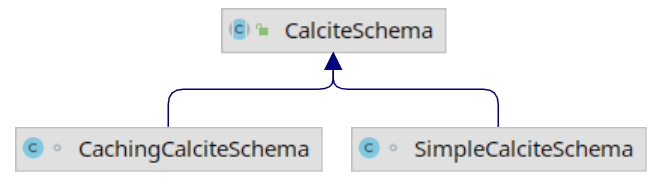
CatalogReader用于读取表的元数据信息, 在绝大多数情况下只需使用其默认实现CalciteCatalogReader即可, 如有特殊需求, 可继承CalciteCatalogReader进行实现. 这里重点介绍一下CalciteCatalogReader构造函数中需要的RelDataTypeFactory. 它是一个数据类型描述符的工厂, 定义了用于实例化和组合SQL, Java和集合类型的方法. 在我们代码的SimpleTable.getRowType()函数中会用到.
可以看到Calcite中用于提供元数据的接口还是有点绕的, 特别是Schema相关的接口. 不过好在在实践中我们通常只需要实现相应的Schema接口, 用于读取特定数据源的元数据信息即可.
Calcite SQL验证相关概念
在介绍SQL验证流程之前, 我们先介绍一下Calcite为实现SQL验证引入的一些概念.
在通用编程语言中都有作用域的概念, 只能使用当前作用域或父作用域内的函数或变量, 比如C语言的函数是一个作用域, 函数内部只能使用函数内定义的局部变量, 或定义在全局作用域内的全局变量或函数, 但是不能使用定义在其他函数内部的局部变量. SQL语言中同样有作用域, 在Calcite中称为Scope.
1 | SELECT expr1 |
我们以上述SQL语句来说明Calcite中关于Scope的概念. 在查询的各个位置可用的作用域如下:
expr1只能看见t1,t2和q3, 也就是说expr1只能使用t1,t2,q3中存在的列名.expr2只能看见t3.expr3只能看见t4.expr4只能看见t1,t2,q3, 加上SELECT子句中定义的任何别名.
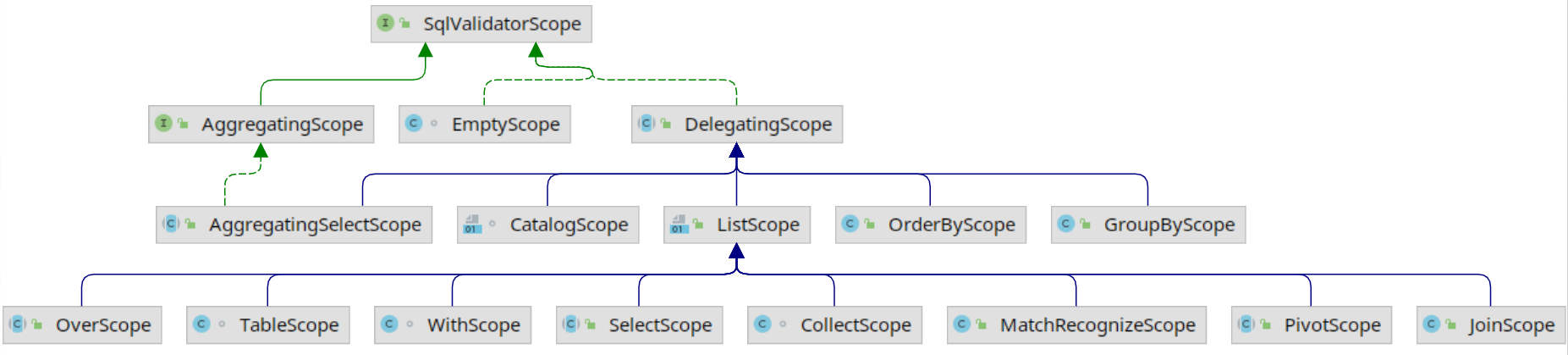
在Calcite中Scope由SqlValidateScope表示, 其类继承图如下.
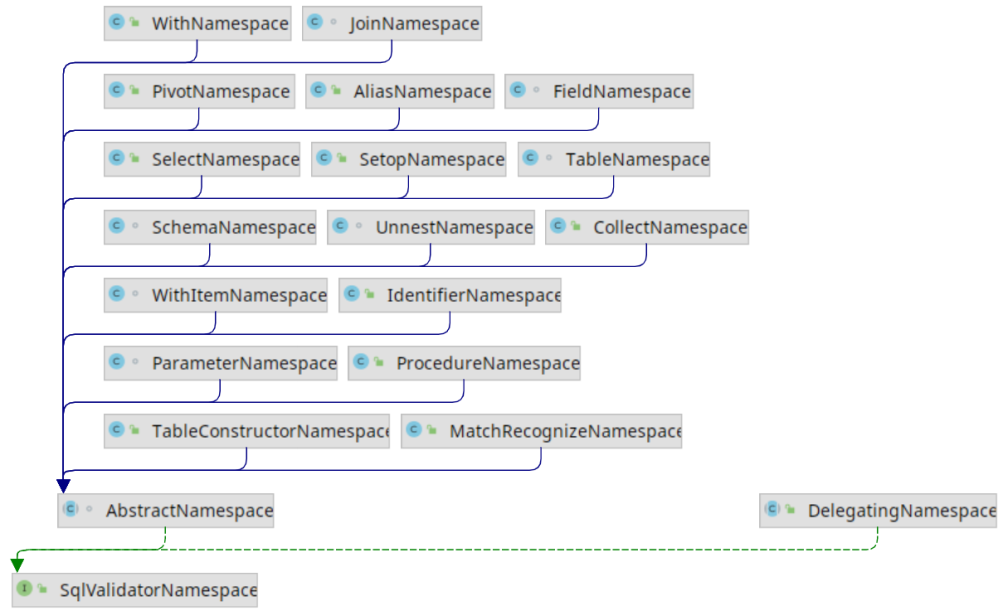
SQL语句需要从一个源中获取数据, Calcite将数据源抽象为命名空间Namespace. Namespace是一个抽象概念, 它既可以表示一个表, 也可以是视图或子查询. 上述SQL语句中有4个Namespace: t1, t2, (SELECT expr2 FROM t3) AS q3和(SELECT expr3 FROM t4). Calcite中使用SqlValidatorNamespace表示Namespace, 它的类继承图如下.
Calcite SQL验证流程
在SQL语句中, DDL语句是不需要验证的, DQL和DML语句都需要验证. 由于各类语句的验证流程在细节上存在差别, 这里以最常见的SELECT语句为例, 讲述其验证过程. 整个SELECT语句验证流程中的函数调用链如下.
1 | SqlValidator.validate() // SQL验证入口 |
在验证流程中有三个主要的函数: SqlValidatorImpl.performUnconditionalRewrites(), SqlValidatorImpl.registerQuery()和SqlSelect.validate(), 下文将对他们进行详细的说明.
SQL重写
SQL重写用于将解析阶段得到的解析树重写为统一的格式, 方便下一步的处理. 由于SqlValidatorImpl.performUnconditionalRewrites()函数的实现十分复杂, 这里也就不详细分析重写的过程了. 而是通过两个具体的例子来说明重写的效果.
第一个例子是带有ORDER BY的SELECT语句, 在解析阶段这类语句会被解析为SqlOrderBy节点, 不过SqlOrderBy是一个纯语法节点, 在重写阶段会转化为SqlSelect节点. 其实我们看一下这两个类的定义就能明白这种转化是如何进行的, 核心代码如下. 对于SELECT ... ORDER BY ...语句, 在解析阶段生成的SqlOrderBy节点中query变量保存了SELECT ...部分的解析结果, 它其实是一个SqlSelect实例, ORDER BY后面的字段列表保存在orderList中. 在重写之后, SqlOrderBy中的orderList被移动到SqlSelect的orderBy中.
1 | public class SqlOrderBy extends SqlCall { |
第二个例子是DELETE语句, 在解析阶段这类语句会被解析为SqlDelete节点, 其关键属性如以下代码所示. 在解析阶段生成的SqlDelete中sourceSelect为null, 在重写阶段会生成sourceSelect用于指示如何从表中查询需要删除的记录. 比如DELET FROM users WHERE id > 1对应的sourceSelect就是SELECT * FROM users WHERE id > 1.
1 | public class SqlDelete extends SqlCall { |
通过以上例子可以看到重写阶段所作的工作就是对解析树进行一些轻微的调整, 一般情况下这一阶段也不需要任何改动, 只要大概了解其流程即可. 其实如果在解析阶段就生成标准的格式, 就不需要重写了, 只不过这样会让解析器的代码变得冗长, 这应该也是Calcite把一些重写工作放到验证阶段的原因.
注册Scope和Namespace
在真正进行验证之前, 还需要调用SqlValidatorImpl.registerQuery()注册Scope和Namespace. 在这一步Calcite会先遍历一遍整个SQL语句, 为解析树的各个部分生成对应的Scope和Namespace. 解析的结果保存在SqlValidatorImpl的成员变量中, 以下是与解析结果相关的核心代码.
1 | public class SqlValidatorImpl implements SqlValidatorWithHints { |
SQL语句验证
注册完Scope和Namespace之后就可以调用SqlNode.validate()方法进行验证了, 这里Calcite也使用了Visitor模式. 如果读者不了解什么是Visitor模式, 可以参考笔者之前的博文. 简单来说, Visitor模式就是把实现逻辑集中到一个类中, 在这里就是SqlValidatorImpl. 我们可以看下SqlSelect.validate()的实现, 它并没有实现具体的逻辑, 而是调用了传入的SqlValidator的validateQuery方法, 也就是SqlValidatorImpl.validateQuery. 这样带来的一个好处是, 如果我们需要修改验证逻辑, 只需要对SqlValidatorImpl进行修改, 而不需要修改SqlNode的实现类.
1 | public abstract class SqlNode implements Cloneable { |
SqlValidatorImpl.validateQuery是SELECT语句验证的真正入口, 它主要对Scope和Namespace进行了验证, 整个调用逻辑比较复杂, 存在很多递归调用. 如果读者有兴趣可以根据上述调用链逐步调试, 这里不再详细分析.
总结
本文梳理了Calcite SQL验证相关的概念和流程, 由于这部分的代码较为复杂, 存在大量的递归调用, 所以本文也没有详细的分析所有细节. 好在SQL验证这部分不太需要进行修改, 多数情况下只需要理解其整体流程即可. 如果要对扩展的SQL语法进行验证, 可以建立一个统一的基类, 让扩展的SQL语法节点都继承该类, 这样在验证阶段可以对这类节点单独进行验证, 并不一定要修改SqlValidatorImpl类, 从而简化工作.
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送