本文已收录在合集Apche Flink原理与实践 中.
Flink SQL函数丰富了SQL层的数据处理能力, 除了大量的内置函数, Flink还支持用户自定义函数(User-defined function, UDF). 在Flink SQL优化器中, 会对函数进行多层转换, 本文将对此进行详细介绍. 理解了这一流程, 便可为Flink添加更多内置函数, 亦可理解UDF的执行原理与可能出现的问题.
SQL函数分类 在Flink SQL中, 函数可以从多个维度进行分类.
其中一个维度是分类为System(or Built-in) Function和Catalog Funtion. 其中System Function可以直接通过名称引用, 而Catalog Function属于某个Catalog和Database, 因此可以通过catalog.db.func或db.func或直接使用函数名这几种方式引用.
另一个维度可分类为Temporary Function和Persistent Function, 其中Temporary Function一般仅存在于一个会话中, 而Persistent Function一般为System Function或持久化在Catalog中.
通过以上两个维度, 可以将Flink函数分为四种类型:
Temporary system functions: 在TableEnvironment中可以通过createTemporarySystemFunction()创建.
System functions: 由Flink内核提供, 用户无法直接添加, 只有通过修改内核代码后重新编译才能添加.
Temporary catalog functions: 在TableEnvironment中可以通过createTemporaryFunction()创建.
Catalog functions: 在TableEnvironment中可以通过createFunction()创建.
对于UDF来说, 一般还可从函数的输入输出类型区分为:
Scalar Function: 输入输出存在一对一关系, 即输入一行数据输出一行数据, 输入可以有多列, 输出只能有一列.
Table Function: 输入输出存在一对多关系, 即输入一行数据输出零行或多行数据, 输入输出均支持多列.
Aggregate Function: 输入输出存在一对多关系, 即输入多行数据输出一行数据, 输入可以有多列, 输出只能有一列.
Table Aggregate Function: 输入输出存在多对多关系, 即输入多行数据输出多行数据, 输入输出均可有多列. Table Aggregate Function目前无法再SQL中使用, 只能用于Table API.
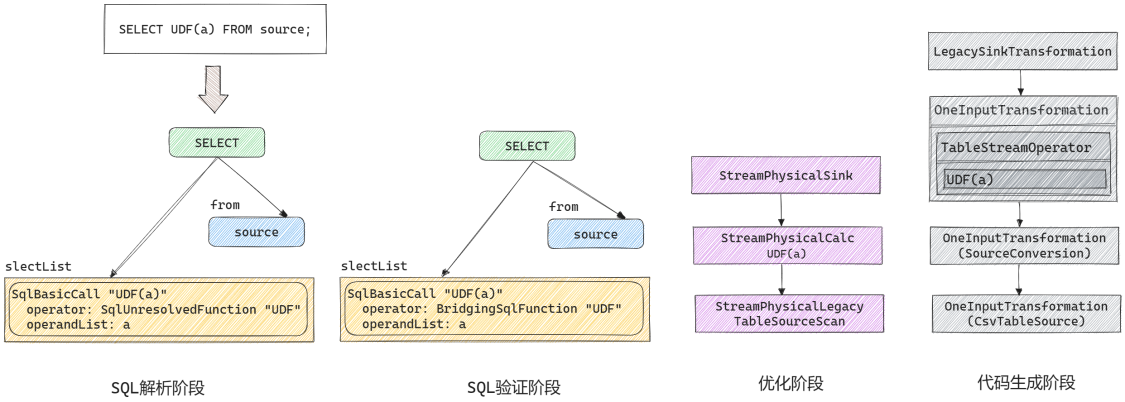
Table Planner处理流程 在Flink SQL中, 函数在SQL的解析阶段, 验证阶段和代码生成阶段都会进行相应的转换, 最终包装在相应的StreamOperator实现类中执行.
以下是一个使用了UDF的SELECT语句的转换过程.
解析阶段 在SQL解析阶段, 所有类型的函数都会被解析为SqlUnresolvedFunction, 这一阶段直接由Calcite实现, 本文不再赘述.
验证阶段 解析阶段仅做语法上的解析, 所有形如f(param)形式的表达式都会被解析为SqlUnresolvedFunction. 验证阶段会验证函数是否已经注册, 对于已注册的函数会根据函数类型转换为SqlFunction的子类型, 并验证其输入输出类型是否符合语义.
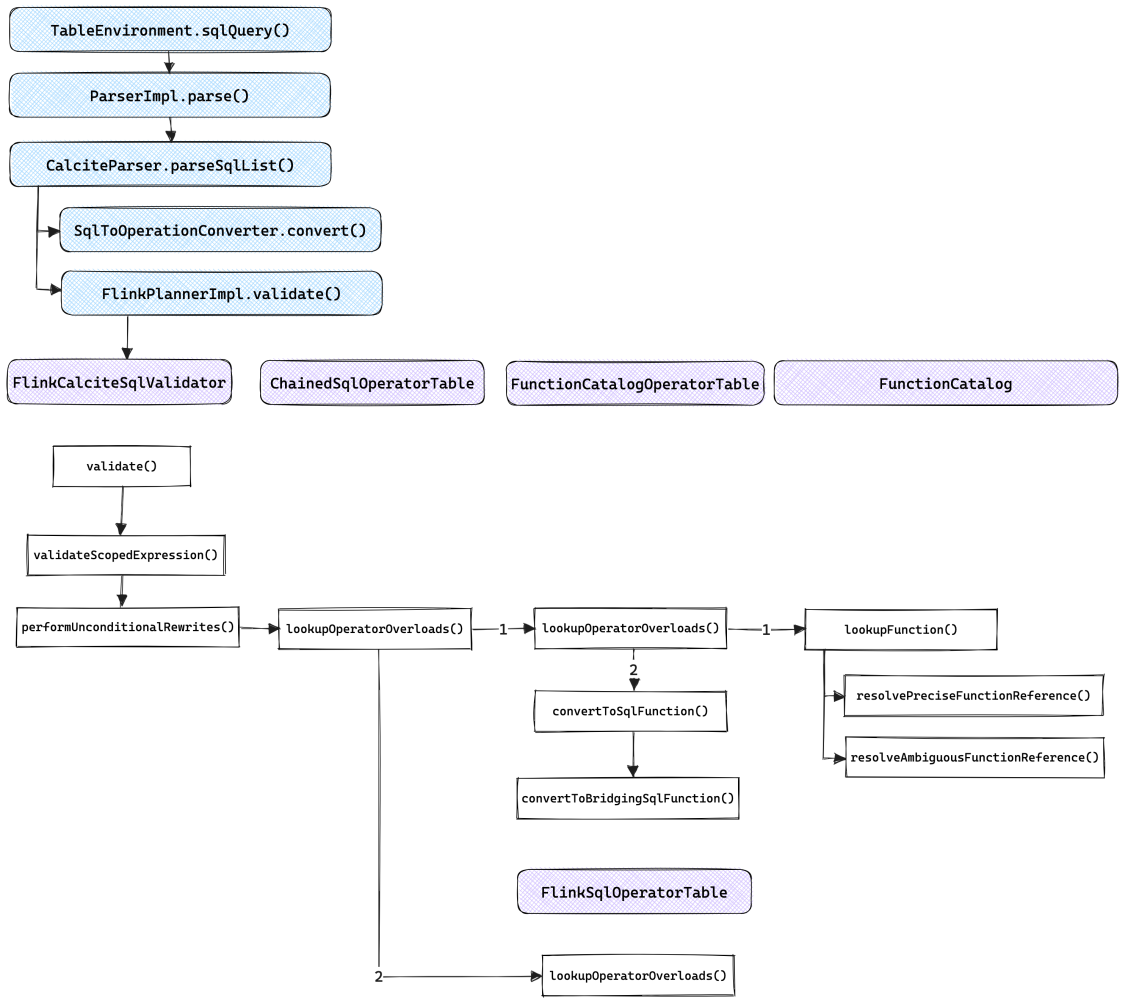
函数查找及转换的整体调用流程如下图所示, 这一流程还是在Calcite的验证框架中执行的.
上图中, FlinkCalciteSqlValidator是SqlValidatorImpl的简单扩展. SqlValidatorImpl通过SqlOperatorTable获取函数元数据, 在Flink中其实现类是FunctionCatalogOperatorTable和FlinkSqlOperatorTable, 并组合在ChainedSqlOperatorTable中. 其中:
FunctionCatalogOperatorTable用来适配FunctionCatalog, 包含用户注册的Catalog Function, 以及定义在BuiltInFunctionDefinitions中的System Function(通过CoreModule加载).FlinkSqlOperatorTable则定义了Flink特有的一些函数, 如TUMBLE, HOP等.
如果使用了未注册的函数, 验证阶段会直接抛出异常. 对于已注册的函数, 会转换为SqlFunction的子类型, 具体来说:
如果是UDF
Scalar Function被转换为BridgingSqlFunction;
Table Function被转换为BridgingSqlFunction.WithTableFunction;
Aggregate Function和Table Aggregate Function被转换为BridgingSqlAggFunction.
如果是内置函数
如果是有Runtime类的函数, 同UDF一样;
否则被转换为SqlFunction或其子类, 这类函数对应的具体类型都在FlinkSqlOperatorTable中定义.
转换为SqlFunction之后会对函数的输入输出类型进行语义验证, 验证实现在SqlOperator.checkOperandTypes()中(SqlFunction是SqlOperator的子类), 会调用SqlOperandTypeChecker进行类型检验, 在Flink中其实现类是TypeInferenceOperandChecker.
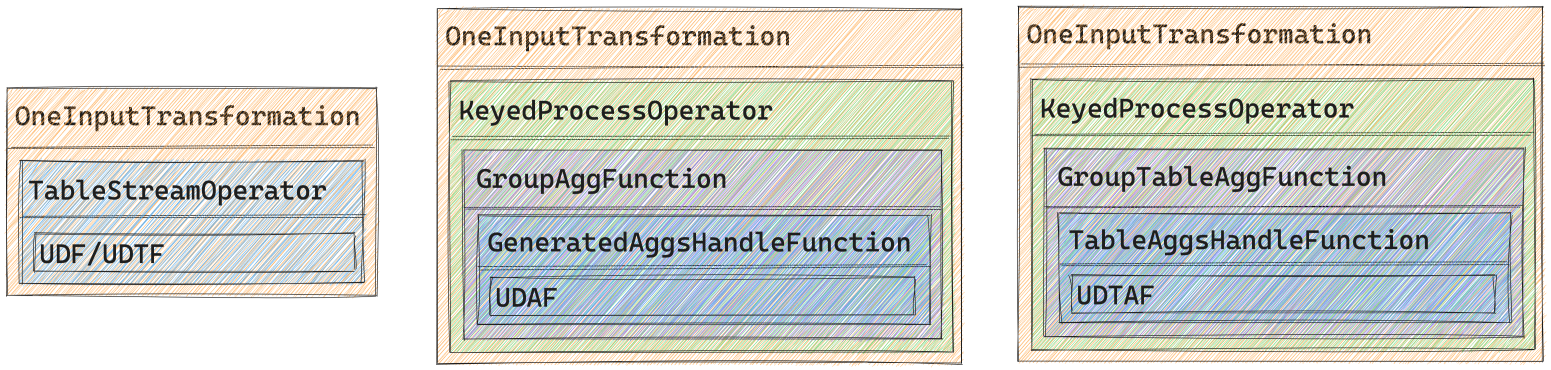
代码生成阶段 无论是解析阶段产出的SqlUnresolvedFunction还是验证阶段产出的SqlFunction都是Calcite定义的, 无法提交给Flink执行引擎运行, 代码生成阶段会将SqlFunction对应的可执行函数嵌入到StreamOperator中. 具体来说, 不同类型函数所生成的Transformation结构如下图所示, 其中蓝色部分均是自动生成的代码, Scalar Function和Table Function均会嵌入到自动生成的TableStreamOperator子类中(生成代码可参考附录一 和附录二 ), 在其中的processElement()函数中会调用用户提供的UDF/UDTF进行处理; Aggregate Function会嵌入到自动生成的GeneratedAggsHandleFunction中(生成代码可参考附录三 ); Table Aggregate Function会嵌入到自动生成的TableAggsHandleFunction中(生成代码可参考附录四 ).
函数相关的代码生成的逻辑在ExprCodeGenerator.generateCallExpression()中, 它会根据函数的类型选择对应的生成方法.
最佳实践 新增系统函数 尽管Flink开源版本已经提供了大量的内置函数, 但在实际使用中仍有扩展空间. 如果要添加系统函数, 通过上文的分析可知存在多种方法:
如果仅需扩展少数几个函数, 可直接在BuiltInFunctionDefinitions或FlinkSqlOperatorTable中增加函数定义即可;
如果需要扩展某一类函数, 如支持空间计算的函数, 可创建一个继承自ReflectiveSqlOperatorTable的FlinkSqlSpatialOperatorTable, 在其中定义相关函数, 减少对已有代码的侵入. 并在PlannerContext.getBuiltinSqlOperatorTable()返回的ChainedSqlOperatorTable中添加新增的FlinkSqlSpatialOperatorTable;
如果是为了添加兼容某个已有系统的函数, 可以参考Hive的实现, 添加一个HiveModule来加载对应的函数.
UDF重复调用问题 Flink SQL的自定义Scalar Function, 在以下两种SQL Pattern中存在重复调用的问题:
第一种是在SELECT列和WHERE条件中都使用了UDF进行计算;
第二种是在子查询中使用了UDF, 并在外层查询中引用了UDF的计算结果.
以下是重复调用的SQL示例, 读者可运行UDFExample 查看结果以加深理解.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 SELECT split_index(UDF(b), '|' , 0 ) AS y, split_index(UDF(b), '|' , 1 ) AS m, split_index(UDF(b), '|' , 2 ) AS d FROM source WHERE UDF(b) <> 'NULL' SELECT split_index(r, '|' , 0 ) AS y, split_index(r, '|' , 1 ) AS m, split_index(r, '|' , 2 ) AS d FROM ( SELECT UDF(b) AS r FROM source );
为了搞清楚上述SQL出现UDF重复调用的原因, 我们先看一下它们对应的逻辑和物理表达式.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 -- 情况一逻辑表达式 LogicalSink(table=[*anonymous_collect$1*], fields=[y, m, d]) LogicalProject(y=[SPLIT_INDEX(UDF($1), _UTF-16LE'|', 0)], m=[SPLIT_INDEX(UDF($1), _UTF-16LE'|', 1)], d=[SPLIT_INDEX(UDF($1), _UTF-16LE'|', 2)]) LogicalFilter(condition=[<>(UDF($1), _UTF-16LE'NULL')]) LogicalTableScan(table=[[default_catalog, default_database, source, source: [CsvTableSource(read fields: a, b)]]]) -- 情况一物理表达式 StreamPhysicalSink(table=[*anonymous_collect$1*], fields=[y, m, d]) StreamPhysicalCalc(select=[SPLIT_INDEX(UDF(b), '|', 0) AS y, SPLIT_INDEX(UDF(b), '|', 1) AS m, SPLIT_INDEX(UDF(b), '|', 2) AS d], where=[<>(UDF(b), 'NULL')]) StreamPhysicalLegacyTableSourceScan(table=[[default_catalog, default_database, source, source: [CsvTableSource(read fields: b)]]], fields=[b]) -- 情况二逻辑表达式 LogicalSink(table=[*anonymous_collect$1*], fields=[y, m, d]) LogicalProject(y=[SPLIT_INDEX(UDF($1), _UTF-16LE'|', 0)], m=[SPLIT_INDEX(UDF($1), _UTF-16LE'|', 1)], d=[SPLIT_INDEX(UDF($1), _UTF-16LE'|', 2)]) LogicalTableScan(table=[[default_catalog, default_database, source, source: [CsvTableSource(read fields: a, b)]]]) -- 情况二物理表达式 StreamPhysicalSink(table=[*anonymous_collect$1*], fields=[y, m, d]) StreamPhysicalCalc(select=[SPLIT_INDEX(UDF(b), '|', 0) AS y, SPLIT_INDEX(UDF(b), '|', 1) AS m, SPLIT_INDEX(UDF(b), '|', 2) AS d]) StreamPhysicalLegacyTableSourceScan(table=[[default_catalog, default_database, source, source: [CsvTableSource(read fields: b)]]], fields=[b])
可以看到, 上述两种情况的物理表达式是基本相同的, 所有UDF相关的计算都会合并到StreamPhysicalCalc中. UDF重复调用的本质原因就是Flink Table Planner在对StreamPhysicalCalc进行代码生成时, 未考虑UDF表达式的可重用性(情况二生成的代码可参考附录五 ). 实际上, Flink UDF都实现了FunctionDefinition接口, 其中的isDeterministic()可让用户返回一个boolean值以指示当前UDF是否具有确定性. 在代码生成时可以借助该方法判断UDF结果是否可重用, 然而Flink目前的实现完全忽略了该信息, FLINK-21573 报告了该问题, 不过目前看还没有下文.
重复调用对于计算复杂度高的UDF会产生性能问题, 此外如果在UDF中使用了状态也可能导致意外错误. 要从根本上解决这一问题, 需要更改Flink Codegen实现, 在Codegen时根据UDF是否确定决定是否重用计算值, 具体实现可参考这一Commit , 修改后生成的代码如附录六 所示, 只会调用一次UDF.
如果无法修改Flink源码, 在实践中也可以通过以下方法规避:
在Flink 1.17及之前的版本中, 可以将UDF改为UDTF, 虽然UDTF的写法略微复杂, 但是由于在代码生成阶段都是在TableStreamOperator中调用, 性能上不会有太大差距.
从Flink 1.18开始, 将多个Project的合并由在SqlNode到RelNode的转换过程中实现, 变成了由优化器实现, 具体可参考FLINK-20887 . 在底层Project列涉及非确定的UDF计算时, 仅在顶层Project仅引用一次底层Project计算列时才能将两个Project合并. 以上述情况二的SQL为例, 如果让UDF的isDeterministic()方法返回false, 那么生成的表达式将如下所示, UDF的计算会在一个单独的StreamPhysicalCalc中, 这样就避免了重复计算.
1 2 3 4 5 6 7 8 9 LogicalSink(table=[*anonymous_collect$1*], fields=[y, m, d]) LogicalProject(y=[SPLIT_INDEX($0, _UTF-16LE'|', 0)], m=[SPLIT_INDEX($0, _UTF-16LE'|', 1)], d=[SPLIT_INDEX($0, _UTF-16LE'|', 2)]) LogicalProject(r=[UDF($1)]) LogicalTableScan(table=[[default_catalog, default_database, source, source: [CsvTableSource(read fields: a, b)]]]) StreamPhysicalSink(table=[*anonymous_collect$1*], fields=[y, m, d]) StreamPhysicalCalc(select=[SPLIT_INDEX(r, '|', 0) AS y, SPLIT_INDEX(r, '|', 1) AS m, SPLIT_INDEX(r, '|', 2) AS d]) StreamPhysicalCalc(select=[UDF(b) AS r]) StreamPhysicalLegacyTableSourceScan(table=[[default_catalog, default_database, source, source: [CsvTableSource(read fields: b)]]], fields=[b])
对于情况一, 我们可以将SQL做如下修改, 这样其效果与情况二将类似.
1 2 3 4 5 6 7 8 SELECT split_index(r, '|' , 0 ) AS y, split_index(r, '|' , 1 ) AS m, split_index(r, '|' , 2 ) AS d FROM ( SELECT UDF(b) AS r FROM source ) WHERE r <> 'NULL' ;
总结 本文从Flink SQL源码的角度分析了SQL函数的实现原理, 通过本文可以了解到, SQL函数是如何从用户定义的函数类转换为Flink可执行代码. 了解了这一过程之后, 在编写和使用UDF时便能妥善处理UDF中的状态, 并规避在使用UDF时可能出现的问题.
参考 [1] Flink Documentation - Table API & SQL - Functions - Overview [FLINK-21573] Support expression reuse in codegen [FLINK-20887] Non-deterministic functions return different values even if it is referred with the same column name
附录 生成的代码均做了一些简化, 如去掉全路径包名, 变量名称简化等, 以方便阅读.
附录一 SELECT UDF(b) FROM source WHERE UDF(b) IS NOT NULL;生成的与UDF计算相关的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 public class StreamExecCalc $11 extends TableStreamOperator implements OneInputStreamOperator { private final Object[] references; private transient StringDataSerializer typeSerializer$3 ; private transient UDF udf; private transient StringStringConverter converter$5 ; BoxedWrapperRowData out = new BoxedWrapperRowData(1 ); private final StreamRecord outElement = new StreamRecord(null ); public StreamExecCalc$11 ( Object[] references, StreamTask task, StreamConfig config, Output output, ProcessingTimeService processingTimeService) throws Exception { this .references = references; typeSerializer$3 = (((StringDataSerializer) references[0 ])); udf = (((UDF) references[1 ])); converter$5 = (((StringStringConverter) references[2 ])); udf = (((UDF) references[3 ])); this .setup(task, config, output); if (this instanceof AbstractStreamOperator) { ((AbstractStreamOperator) this ).setProcessingTimeService(processingTimeService); } } @Override public void open () throws Exception super .open(); udf.open(new FunctionContext(getRuntimeContext())); converter$5 .open(getRuntimeContext().getUserCodeClassLoader()); } @Override public void processElement (StreamRecord element) throws Exception RowData in1 = (RowData) element.getValue(); BinaryStringData field$2 ; boolean isNull$2 ; BinaryStringData field$4 ; String externalResult$6 ; BinaryStringData result$7 ; boolean isNull$7 ; String externalResult$9 ; BinaryStringData result$10 ; boolean isNull$10 ; isNull$2 = in1.isNullAt(0 ); field$2 = BinaryStringData.EMPTY_UTF8; if (!isNull$2 ) { field$2 = ((BinaryStringData) in1.getString(0 )); } field$4 = field$2 ; if (!isNull$2 ) { field$4 = (BinaryStringData) (typeSerializer$3 .copy(field$4 )); } externalResult$6 = (String) udf .eval(isNull$2 ? null : ((String) converter$5 .toExternal((BinaryStringData) field$4 ))); isNull$7 = externalResult$6 == null ; result$7 = BinaryStringData.EMPTY_UTF8; if (!isNull$7 ) { result$7 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$6 ); } boolean result$8 = !isNull$7 ; if (result$8 ) { out.setRowKind(in1.getRowKind()); externalResult$9 = (String) udf .eval(isNull$2 ? null : ((String) converter$5 .toExternal((BinaryStringData) field$4 ))); isNull$10 = externalResult$9 == null ; result$10 = BinaryStringData.EMPTY_UTF8; if (!isNull$10 ) { result$10 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$9 ); } if (isNull$10 ) { out.setNullAt(0 ); } else { out.setNonPrimitiveValue(0 , result$10 ); } output.collect(outElement.replace(out)); } } @Override public void finish () throws Exception super .finish(); } @Override public void close () throws Exception super .close(); udf.close(); } }
附录二 SELECT y, m, d FROM source, LATERAL TABLE(UDTF(b)) AS T(y, m, d);生成的与UDTF计算相关的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 public class StreamExecCorrelate $12 extends TableStreamOperator implements OneInputStreamOperator { private final Object[] references; private TableFunctionCollector$4 correlateCollector$2 = null ; private transient UDTF udtf; private transient StringStringConverter converter$7 ; private transient RowRowConverter converter$9 ; private TableFunctionResultConverterCollector$10 resultConverterCollector$11 = null ; private final StreamRecord outElement = new StreamRecord(null ); public StreamExecCorrelate$12 ( Object[] references, StreamTask task, StreamConfig config, Output output, ProcessingTimeService processingTimeService) throws Exception { this .references = references; udtf = (((UDTF) references[0 ])); converter$7 = (((StringStringConverter) references[1 ])); converter$9 = (((RowRowConverter) references[2 ])); this .setup(task, config, output); if (this instanceof AbstractStreamOperator) { ((AbstractStreamOperator) this ).setProcessingTimeService(processingTimeService); } } @Override public void open () throws Exception super .open(); correlateCollector$2 = new TableFunctionCollector$4 (); correlateCollector$2 .setRuntimeContext(getRuntimeContext()); correlateCollector$2 .open(new Configuration()); udtf.open(new FunctionContext(getRuntimeContext())); converter$7 .open(getRuntimeContext().getUserCodeClassLoader()); converter$9 .open(getRuntimeContext().getUserCodeClassLoader()); resultConverterCollector$11 = new TableFunctionResultConverterCollector$10 (); resultConverterCollector$11 .setRuntimeContext(getRuntimeContext()); resultConverterCollector$11 .open(new Configuration()); udtf.setCollector(resultConverterCollector$11 ); correlateCollector$2 .setCollector(new StreamRecordCollector(output)); resultConverterCollector$11 .setCollector(correlateCollector$2 ); } @Override public void processElement (StreamRecord element) throws Exception RowData in1 = (RowData) element.getValue(); BinaryStringData field$5 ; boolean isNull$5 ; BinaryStringData result$6 ; boolean isNull$6 ; correlateCollector$2 .setInput(in1); correlateCollector$2 .reset(); if (false ) { result$6 = BinaryStringData.EMPTY_UTF8; isNull$6 = true ; } else { isNull$5 = in1.isNullAt(1 ); field$5 = BinaryStringData.EMPTY_UTF8; if (!isNull$5 ) { field$5 = ((BinaryStringData) in1.getString(1 )); } result$6 = field$5 ; isNull$6 = isNull$5 ; } udtf.eval(isNull$6 ? null : ((String) converter$7 .toExternal((BinaryStringData) result$6 ))); } @Override public void finish () throws Exception udtf.finish(); super .finish(); } @Override public void close () throws Exception super .close(); udtf.close(); } public class TableFunctionResultConverterCollector $10 extends WrappingCollector public TableFunctionResultConverterCollector$10 () throws Exception { } @Override public void open (Configuration parameters) throws Exception @Override public void collect (Object record) throws Exception RowData externalResult$8 = (RowData) (RowData) converter$9 .toInternalOrNull((Row) record); if (externalResult$8 != null ) { outputResult(externalResult$8 ); } } @Override public void close () try { } catch (Exception e) { throw new RuntimeException(e); } } } public class TableFunctionCollector $4 extends TableFunctionCollector JoinedRowData joinedRow$3 = new JoinedRowData(); public TableFunctionCollector$4 () throws Exception { } @Override public void open (Configuration parameters) throws Exception @Override public void collect (Object record) throws Exception RowData in1 = (RowData) getInput(); RowData in2 = (RowData) record; joinedRow$3 .replace(in1, in2); joinedRow$3 .setRowKind(in1.getRowKind()); outputResult(joinedRow$3 ); } @Override public void close () try { } catch (Exception e) { throw new RuntimeException(e); } } } }
附录三 SELECT UDAF(a) FROM source GROUP BY a;生成的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 public final class GroupAggsHandler $18 implements AggsHandleFunction private transient UDAF udaf; private transient StructuredObjectConverter converter$8 ; GenericRowData acc$10 = new GenericRowData(1 ); GenericRowData acc$11 = new GenericRowData(1 ); private RowData agg0_acc_internal; private UDAF.Acc agg0_acc_external; GenericRowData aggValue$17 = new GenericRowData(1 ); private StateDataViewStore store; public GroupAggsHandler$18 (Object[] references) throws Exception { udaf = (((UDAF) references[0 ])); converter$8 = (((StructuredObjectConverter) references[1 ])); } private RuntimeContext getRuntimeContext () return store.getRuntimeContext(); } @Override public void open (StateDataViewStore store) throws Exception this .store = store; udaf.open(new FunctionContext(store.getRuntimeContext())); converter$8 .open(getRuntimeContext().getUserCodeClassLoader()); } @Override public void setWindowSize (int windowSize) @Override public void accumulate (RowData accInput) throws Exception long field$13 ; boolean isNull$13 ; isNull$13 = accInput.isNullAt(1 ); field$13 = -1L ; if (!isNull$13 ) { field$13 = accInput.getLong(1 ); } udaf.accumulate(agg0_acc_external, isNull$13 ? null : ((Long) field$13 )); } @Override public void retract (RowData retractInput) throws Exception throw new RuntimeException("This function not require retract method, but the retract method is called." ); } @Override public void merge (RowData otherAcc) throws Exception throw new RuntimeException("This function not require merge method, but the merge method is called." ); } @Override public void setAccumulators (RowData acc) throws Exception RowData field$12 ; boolean isNull$12 ; isNull$12 = acc.isNullAt(0 ); field$12 = null ; if (!isNull$12 ) { field$12 = acc.getRow(0 , 1 ); } agg0_acc_internal = field$12 ; agg0_acc_external = (UDAF.Acc) converter$8 .toExternal((RowData) agg0_acc_internal); } @Override public void resetAccumulators () throws Exception agg0_acc_external = (UDAF.Acc) udaf.createAccumulator(); agg0_acc_internal = (RowData) converter$8 .toInternalOrNull((UDAF.Acc) agg0_acc_external); } @Override public RowData getAccumulators () throws Exception acc$11 = new GenericRowData(1 ); agg0_acc_internal = (RowData) converter$8 .toInternalOrNull((UDAF.Acc) agg0_acc_external); if (false ) { acc$11 .setField(0 , null ); } else { acc$11 .setField(0 , agg0_acc_internal); } return acc$11 ; } @Override public RowData createAccumulators () throws Exception acc$10 = new GenericRowData(1 ); RowData acc_internal$9 = (RowData) (RowData) converter$8 .toInternalOrNull((UDAF.Acc) udaf.createAccumulator()); if (false ) { acc$10 .setField(0 , null ); } else { acc$10 .setField(0 , acc_internal$9 ); } return acc$10 ; } @Override public RowData getValue () throws Exception aggValue$17 = new GenericRowData(1 ); Long value_external$14 = (Long) udaf.getValue(agg0_acc_external); Long value_internal$15 = value_external$14 ; boolean valueIsNull$16 = value_internal$15 == null ; if (valueIsNull$16 ) { aggValue$17 .setField(0 , null ); } else { aggValue$17 .setField(0 , value_internal$15 ); } return aggValue$17 ; } @Override public void cleanup () throws Exception @Override public void close () throws Exception udaf.close(); } }
附录四
1 2 3 4 5 tEnv.from("source" ) .groupBy($("a" )) .flatAggregate(call("UDTAF" , $("a" )).as("value" , "rank" )) .select($("value" ), $("rank" )) .execute().print();
上述UDTAF相关部分生成的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 public final class GroupTableAggHandler $12 implements TableAggsHandleFunction private transient UDTAF udtaf; private transient StructuredObjectConverter converter$2 ; GenericRowData acc$4 = new GenericRowData(1 ); GenericRowData acc$5 = new GenericRowData(1 ); private RowData agg0_acc_internal; private UDTAF.Acc agg0_acc_external; private transient StructuredObjectConverter converter$11 ; private StateDataViewStore store; private ConvertCollector convertCollector; public GroupTableAggHandler$12 (java.lang.Object[] references) throws Exception { udtaf = (((UDTAF) references[0 ])); converter$2 = (((StructuredObjectConverter) references[1 ])); converter$11 = (((StructuredObjectConverter) references[2 ])); convertCollector = new ConvertCollector(references); } private RuntimeContext getRuntimeContext () return store.getRuntimeContext(); } @Override public void open (StateDataViewStore store) throws Exception this .store = store; udtaf.open(new FunctionContext(store.getRuntimeContext())); converter$2 .open(getRuntimeContext().getUserCodeClassLoader()); converter$11 .open(getRuntimeContext().getUserCodeClassLoader()); } @Override public void accumulate (RowData accInput) throws Exception int field$7 ; boolean isNull$7 ; isNull$7 = accInput.isNullAt(0 ); field$7 = -1 ; if (!isNull$7 ) { field$7 = accInput.getInt(0 ); } udtaf.accumulate(agg0_acc_external, isNull$7 ? null : ((java.lang.Integer) field$7 )); } @Override public void retract (RowData retractInput) throws Exception throw new java.lang.RuntimeException("This function not require retract method, but the retract method is called." ); } @Override public void merge (RowData otherAcc) throws Exception throw new java.lang.RuntimeException("This function not require merge method, but the merge method is called." ); } @Override public void setAccumulators (RowData acc) throws Exception RowData field$6 ; boolean isNull$6 ; isNull$6 = acc.isNullAt(0 ); field$6 = null ; if (!isNull$6 ) { field$6 = acc.getRow(0 , 2 ); } agg0_acc_internal = field$6 ; agg0_acc_external = (UDTAF.Acc) converter$2 .toExternal((RowData) agg0_acc_internal); } @Override public void resetAccumulators () throws Exception agg0_acc_external = (UDTAF.Acc) udtaf.createAccumulator(); agg0_acc_internal = (RowData) converter$2 .toInternalOrNull((UDTAF.Acc) agg0_acc_external); } @Override public RowData getAccumulators () throws Exception acc$5 = new GenericRowData(1 ); agg0_acc_internal = (RowData) converter$2 .toInternalOrNull((UDTAF.Acc) agg0_acc_external); if (false ) { acc$5 .setField(0 , null ); } else { acc$5 .setField(0 , agg0_acc_internal); } return acc$5 ; } @Override public RowData createAccumulators () throws Exception acc$4 = new GenericRowData(1 ); RowData acc_internal$3 = (RowData) (RowData) converter$2 .toInternalOrNull((UDTAF.Acc) udtaf.createAccumulator()); if (false ) { acc$4 .setField(0 , null ); } else { acc$4 .setField(0 , acc_internal$3 ); } return acc$4 ; } @Override public void emitValue (Collector<RowData> out, RowData key, boolean isRetract) throws Exception { convertCollector.reset(key, isRetract, out); udtaf.emitValue(agg0_acc_external, convertCollector); } @Override public void cleanup () throws Exception @Override public void close () throws Exception udtaf.close(); } private class ConvertCollector implements Collector private Collector<RowData> out; private RowData key; private utils.JoinedRowData result; private boolean isRetract = false ; private transient UDTAF udtaf; private transient StructuredObjectConverter converter$2 ; GenericRowData acc$4 = new GenericRowData(1 ); GenericRowData acc$5 = new GenericRowData(1 ); private RowData agg0_acc_internal; private UDTAF.Acc agg0_acc_external; private transient StructuredObjectConverter converter$11 ; public ConvertCollector (java.lang.Object[] references) throws Exception udtaf = (((UDTAF) references[0 ])); converter$2 = (((StructuredObjectConverter) references[1 ])); converter$11 = (((StructuredObjectConverter) references[2 ])); result = new utils.JoinedRowData(); } public void reset ( RowData key, boolean isRetract, Collector<RowData> out) this .key = key; this .isRetract = isRetract; this .out = out; } public RowData convertToRowData (Object recordInput$8 ) throws Exception GenericRowData convertResult = new GenericRowData(2 ); RowData in1 = (RowData) (RowData) converter$11 .toInternalOrNull((Tuple2) recordInput$8 ); int field$9 ; boolean isNull$9 ; int field$10 ; boolean isNull$10 ; isNull$9 = in1.isNullAt(0 ); field$9 = -1 ; if (!isNull$9 ) { field$9 = in1.getInt(0 ); } isNull$10 = in1.isNullAt(1 ); field$10 = -1 ; if (!isNull$10 ) { field$10 = in1.getInt(1 ); } if (isNull$9 ) { convertResult.setField(0 , null ); } else { convertResult.setField(0 , field$9 ); } if (isNull$10 ) { convertResult.setField(1 , null ); } else { convertResult.setField(1 , field$10 ); } return convertResult; } @Override public void collect (Object recordInput$8 ) throws Exception RowData tempRowData = convertToRowData(recordInput$8 ); result.replace(key, tempRowData); if (isRetract) { result.setRowKind(RowKind.DELETE); } else { result.setRowKind(RowKind.INSERT); } out.collect(result); } @Override public void close () out.close(); } } }
附录五
1 2 3 4 5 6 7 SELECT split_index(r, '|' , 0 ) AS y, split_index(r, '|' , 1 ) AS m, split_index(r, '|' , 2 ) AS d FROM ( SELECT UDF(b) AS r FROM source );
上述SQL在未改进前生成的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 public class StreamExecCalc $19 extends TableStreamOperator implements OneInputStreamOperator { private final Object[] references; private transient StringDataSerializer typeSerializer$3 ; private transient UDF udf; private transient StringStringConverter converter$5 ; private final BinaryStringData str$8 = BinaryStringData.fromString("|" ); BoxedWrapperRowData out = new BoxedWrapperRowData(3 ); private final StreamRecord outElement = new StreamRecord(null ); public StreamExecCalc$19 ( Object[] references, StreamTask task, StreamConfig config, Output output, ProcessingTimeService processingTimeService) throws Exception { this .references = references; typeSerializer$3 = (((StringDataSerializer) references[0 ])); udf = (((UDF) references[1 ])); converter$5 = (((StringStringConverter) references[2 ])); udf = (((UDF) references[3 ])); udf = (((UDF) references[4 ])); this .setup(task, config, output); if (this instanceof AbstractStreamOperator) { ((AbstractStreamOperator) this ) .setProcessingTimeService(processingTimeService); } } @Override public void open () throws Exception super .open(); udf.open(new org.apache.flink.table.functions.FunctionContext(getRuntimeContext())); converter$5 .open(getRuntimeContext().getUserCodeClassLoader()); } @Override public void processElement (StreamRecord element) throws Exception RowData in1 = (RowData) element.getValue(); BinaryStringData field$2 ; boolean isNull$2 ; BinaryStringData field$4 ; String externalResult$6 ; BinaryStringData result$7 ; boolean isNull$7 ; boolean isNull$9 ; BinaryStringData result$10 ; String externalResult$11 ; BinaryStringData result$12 ; boolean isNull$12 ; boolean isNull$13 ; BinaryStringData result$14 ; String externalResult$15 ; BinaryStringData result$16 ; boolean isNull$16 ; boolean isNull$17 ; BinaryStringData result$18 ; isNull$2 = in1.isNullAt(0 ); field$2 = BinaryStringData.EMPTY_UTF8; if (!isNull$2 ) { field$2 = ((BinaryStringData) in1.getString(0 )); } field$4 = field$2 ; if (!isNull$2 ) { field$4 = (BinaryStringData) (typeSerializer$3 .copy(field$4 )); } out.setRowKind(in1.getRowKind()); externalResult$6 = (String) udf .eval(isNull$2 ? null : ((String) converter$5 .toExternal((BinaryStringData) field$4 ))); isNull$7 = externalResult$6 == null ; result$7 = BinaryStringData.EMPTY_UTF8; if (!isNull$7 ) { result$7 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$6 ); } isNull$9 = isNull$7 || false || false ; result$10 = BinaryStringData.EMPTY_UTF8; if (!isNull$9 ) { result$10 = BinaryStringData.fromString(SqlFunctionUtils.splitIndex(result$7 .toString(),((BinaryStringData) str$8 ).toString(),((int ) 0 ))); isNull$9 = (result$10 == null ); } if (isNull$9 ) { out.setNullAt(0 ); } else { out.setNonPrimitiveValue(0 , result$10 ); } externalResult$11 = (String) udf .eval(isNull$2 ? null : ((String) converter$5 .toExternal((BinaryStringData) field$4 ))); isNull$12 = externalResult$11 == null ; result$12 = BinaryStringData.EMPTY_UTF8; if (!isNull$12 ) { result$12 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$11 ); } isNull$13 = isNull$12 || false || false ; result$14 = BinaryStringData.EMPTY_UTF8; if (!isNull$13 ) { result$14 = BinaryStringData.fromString(SqlFunctionUtils.splitIndex(result$12 .toString(),((BinaryStringData) str$8 ).toString(),((int ) 1 ))); isNull$13 = (result$14 == null ); } if (isNull$13 ) { out.setNullAt(1 ); } else { out.setNonPrimitiveValue(1 , result$14 ); } externalResult$15 = (String) udf .eval(isNull$2 ? null : ((String) converter$5 .toExternal((BinaryStringData) field$4 ))); isNull$16 = externalResult$15 == null ; result$16 = BinaryStringData.EMPTY_UTF8; if (!isNull$16 ) { result$16 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$15 ); } isNull$17 = isNull$16 || false || false ; result$18 = BinaryStringData.EMPTY_UTF8; if (!isNull$17 ) { result$18 = BinaryStringData.fromString(SqlFunctionUtils.splitIndex(result$16 .toString(),((BinaryStringData) str$8 ).toString(),((int ) 2 ))); isNull$17 = (result$18 == null ); } if (isNull$17 ) { out.setNullAt(2 ); } else { out.setNonPrimitiveValue(2 , result$18 ); } output.collect(outElement.replace(out)); } @Override public void finish () throws Exception super .finish(); } @Override public void close () throws Exception super .close(); udf.close(); } }
附录六
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 public class StreamExecCalc $19 extends TableStreamOperator implements OneInputStreamOperator { private final Object[] references; private transient StringDataSerializer typeSerializer$3 ; private transient UDF udf; private transient StringStringConverter converter$5 ; private final BinaryStringData str$8 = BinaryStringData.fromString("|" ); BoxedWrapperRowData out = new BoxedWrapperRowData(3 ); private final StreamRecord outElement = new StreamRecord(null ); public StreamExecCalc$19 ( Object[] references, StreamTask task, StreamConfig config, Output output, ProcessingTimeService processingTimeService) throws Exception { this .references = references; typeSerializer$3 = (((StringDataSerializer) references[0 ])); udf = (((UDF) references[1 ])); converter$5 = (((StringStringConverter) references[2 ])); udf = (((UDF) references[3 ])); udf = (((UDF) references[4 ])); this .setup(task, config, output); if (this instanceof AbstractStreamOperator) { ((AbstractStreamOperator) this ).setProcessingTimeService(processingTimeService); } } @Override public void open () throws Exception super .open(); udf.open(new org.apache.flink.table.functions.FunctionContext(getRuntimeContext())); converter$5 .open(getRuntimeContext().getUserCodeClassLoader()); } @Override public void processElement (StreamRecord element) throws Exception RowData in1 = (RowData) element.getValue(); BinaryStringData field$2 ; boolean isNull$2 ; BinaryStringData field$4 ; String externalResult$6 ; BinaryStringData result$7 ; boolean isNull$7 ; boolean isNull$9 ; BinaryStringData result$10 ; String externalResult$11 ; BinaryStringData result$12 ; boolean isNull$12 ; boolean isNull$13 ; BinaryStringData result$14 ; String externalResult$15 ; BinaryStringData result$16 ; boolean isNull$16 ; boolean isNull$17 ; BinaryStringData result$18 ; isNull$2 = in1.isNullAt(0 ); field$2 = BinaryStringData.EMPTY_UTF8; if (!isNull$2 ) { field$2 = ((BinaryStringData) in1.getString(0 )); } field$4 = field$2 ; if (!isNull$2 ) { field$4 = (BinaryStringData) (typeSerializer$3 .copy(field$4 )); } out.setRowKind(in1.getRowKind()); externalResult$6 = (String) udf .eval(isNull$2 ? null : ((String) converter$5 .toExternal((BinaryStringData) field$4 ))) ; isNull$7 = externalResult$6 == null ; result$7 = BinaryStringData.EMPTY_UTF8; if (!isNull$7 ) { result$7 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$6 ); } isNull$9 = isNull$7 || false || false ; result$10 = BinaryStringData.EMPTY_UTF8; if (!isNull$9 ) { result$10 = BinaryStringData.fromString(SqlFunctionUtils.splitIndex(result$7 .toString(),((BinaryStringData) str$8 ).toString(),((int ) 0 ))); isNull$9 = (result$10 == null ); } if (isNull$9 ) { out.setNullAt(0 ); } else { out.setNonPrimitiveValue(0 , result$10 ); } externalResult$11 = externalResult$6 ; isNull$12 = externalResult$11 == null ; result$12 = BinaryStringData.EMPTY_UTF8; if (!isNull$12 ) { result$12 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$11 ); } isNull$13 = isNull$12 || false || false ; result$14 = BinaryStringData.EMPTY_UTF8; if (!isNull$13 ) { result$14 = BinaryStringData.fromString(SqlFunctionUtils.splitIndex(result$12 .toString(),((BinaryStringData) str$8 ).toString(),((int ) 1 ))); isNull$13 = (result$14 == null ); } if (isNull$13 ) { out.setNullAt(1 ); } else { out.setNonPrimitiveValue(1 , result$14 ); } externalResult$15 = externalResult$6 ; isNull$16 = externalResult$15 == null ; result$16 = BinaryStringData.EMPTY_UTF8; if (!isNull$16 ) { result$16 = (BinaryStringData) converter$5 .toInternalOrNull((String) externalResult$15 ); } isNull$17 = isNull$16 || false || false ; result$18 = BinaryStringData.EMPTY_UTF8; if (!isNull$17 ) { result$18 = BinaryStringData.fromString(SqlFunctionUtils.splitIndex(result$16 .toString(),((BinaryStringData) str$8 ).toString(),((int ) 2 ))); isNull$17 = (result$18 == null ); } if (isNull$17 ) { out.setNullAt(2 ); } else { out.setNonPrimitiveValue(2 , result$18 ); } output.collect(outElement.replace(out)); } @Override public void finish () throws Exception super .finish(); } @Override public void close () throws Exception super .close(); udf.close(); } }
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送