本文已收录在合集Apche Flink原理与实践中.
Changelog起源于数据库领域, 代表变更操作, 可用于增量的数据同步. Flink SQL同样也引入了Changelog记录数据的变更, 来实现增量的数据处理, 只不过在实现上与数据库的Changelog有所不同. Changelog是隐藏在Flink SQL背后的重要概念, 是流与表可以统一的基础, 也是多个流式操作(如Group By)正确性的保障. 本文在介绍Changelog在Flink SQL中的实现原理, 揭开流式SQL背后的神秘面纱.
Changelog概念
数据库中的Changelog
Changelog源自数据库领域, 用于记录数据库的变更操作, 包括插入(INSERT), 更新(UPDATE)和删除(DELETE)操作. MySQL的Binlog就是一种常见的数据库Changelog实现, 可用于增量的数据同步. Change Data Capture(CDC)是一种常用的数据同步技术, 用于监控数据库中的数据变更, 并将这些变更转换为事件流, 以便进行实时处理. Flink SQL为了方便地接入数据库的Changelog数据, 已经支持从多种Changelog格式(如Debezium, Canel等)的数据流创建源表. 甚至为了直接摄取数据库的Binlog, 社区还提供了CDC Connector. 不过这些涉及的都是Flink与外部数据库Changelog的交互与集成, 本文重点讲述Flink SQL内部的Changelog机制.
Flink SQL中的Changelog
Flink SQL内部也采用了Changelog机制来实现准确的增量数据处理. 我们将只包含INSERT操作的Changelog序列称为Append Stream, 而包含其他类型(例如UPDATE)操作的Changelog序列称为Update Stream. 不同于数据库中的Changelog, Flink SQL中的Changelog包含4种类型的操作: INSERT, UPDATE_BEFORE, UPDATE_AFTER, DELET. 可以看到在Flink中, UPDATE被分成了UPDATE_BEFORE和UPDATE_AFTER两个操作, 具体原因下文会进一步介绍. 在Flink SQL中, 每行数据都由RowKind标识变更类型, 其中
INSERT(+I)表示插入行;UPDATE_BEFORE(-U)表示回撤行, 只能与UPDATE_AFTER(+U)一起出现, 用于撤回之前已经向下游发送的行;UPDATE_AFTER(+U)表示更新行, 可以单独出现, 用于执行真正的更新操作;DELETE(-D)表示删除行.
1 | @PublicEvolving |
UPDATE_BEFORE被称为Retraction(回撤), 用于对提前下发的结果进行修正. 在无界聚合及双流Join等场景中常需要进行Retraction操作, Retraction是保证流计算正确性的关键操作之一. 我们通过一个具体的例子来说明为什么需要Retraction以及什么是Retraction. 在电商商品运输过程中, 同一个订单的商品因为各种原因, 物流公司是有可能从A变成B的. 现在我们假设使用如下SQL统计各个物流公司所承运的订单数. 读者可以运行ChangelogGroupExample获得更直观的感受.
1 | -- 源表输入 |
通过上面的例子可以看到, Retraction本质上就是一个删除操作, 不过它总是与UPDATE_AFTER一起出现. 那为什么Flink SQL不像数据库那样, 把变更操作整合为一个复合的UPDATE操作呢, 主要有以下两个原因:
- 不采用复合操作可以简化数据的序列化和反序列化, 将UPDATE拆为UPDATE_BEFORE和UPDATE_AFTER两条记录之后, Flink SQL中的所有Changelog都是同质的数据行, 仅有
RowKind不同. - 在分布式计算环境中, 对于聚合等需要数据Shuffle的计算, 即使用复合的UPDATE, 在一些场景下也需要将其拆分为一条DELETE和一条INSERT记录. 在上述案例中就可能出现这种情况, 如果Group算子存在两个Task, 那么当
+I(001,圆通)这条记录来临时, 由于Deduplicate算子和Group算子之间的数据传输需要根据tms_company进行Hash, 那么Deduplicate算子产生的-U(001,中通)和+U(001,圆通)就需要分别传输到两个下游算子中.
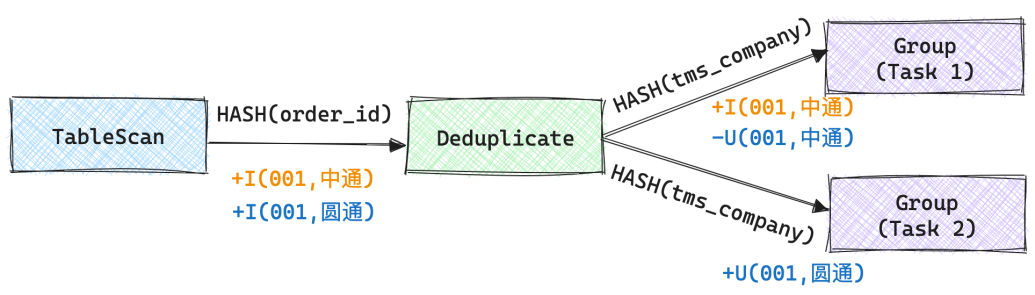
目前在Flink SQL中可能产生Retraction记录的场景有:
- Group Aggregate
- Over Aggregate
- TopN / Deduplication
- Left/Right/Full Join
除了上述场景, 在支持Early Fire或Late Fire的窗口聚合中也会产生回撤记录. 在Flink SQL中, Group Window Aggregate是支持Early Fire或Late Fire的, 启用这一特性的参数定义在WindowEmitStrategy中. 不过一方面这几个参数都是实验性质的, 另一方面Group Window Aggregate已经被基于Window TVF的聚合取代, 而后者不支持Early Fire或Late Fire.
Table Planner处理流程
Flink Table Planner对Changelog语义进行了完善的建模, 在physical_rewrite优化阶段, 会根据StreamPhysicalRel节点的类型及其上下游节点推导出ModifyKind和UpdateKind, 下文将详细介绍推导流程.
相关概念
ChangelogMode
ChangelogMode用于标识算子的变更类型, 是多个不同类型RowKind的集合.
1 | public final class ChangelogMode { |
ModifyKindSetTrait
ModifyKindSetTrait是Calcite中RelTrait的一种实现(如果不了解Calcite可以参考笔者的博文合集Apache Calcite原理与实践), 属于StreamPhysicalRel的其中一种物理属性, 用于标识当前节点的变更类型. 其所持有的变更类型由ModifyKindSet表示, 实现如下, 实际上就是保存了该节点可能出现的ModifyKind类型.
1 | public class ModifyKindSet { |
UpdateKindTrait
UpdateKindSetTrait同样也是RelTrait的一种实现, 属于StreamPhysicalRel的一种物理属性, 用于标识当前节点的更新类型, 具体由UpdateKind表示, 其中:
NONE代表当前节点不存在更新操作;ONLY_UPDATE_AFTER表示当前节点可不产生回撤记录;BEFORE_AND_AFTER表示当前节点需要产生回撤记录.
1 | public enum UpdateKind { |
关系代数优化阶段
在关系代数优化阶段, Changelog相关的处理在physical_rewrite阶段进行. 核心的实现逻辑在FlinkChangelogModeInferenceProgram中. 下文以开头的例子为例介绍关系代数优化阶段的处理流程, 下图是对应的物理表达式及优化后各个算子所对应的ModifyKind和UpdateKind.
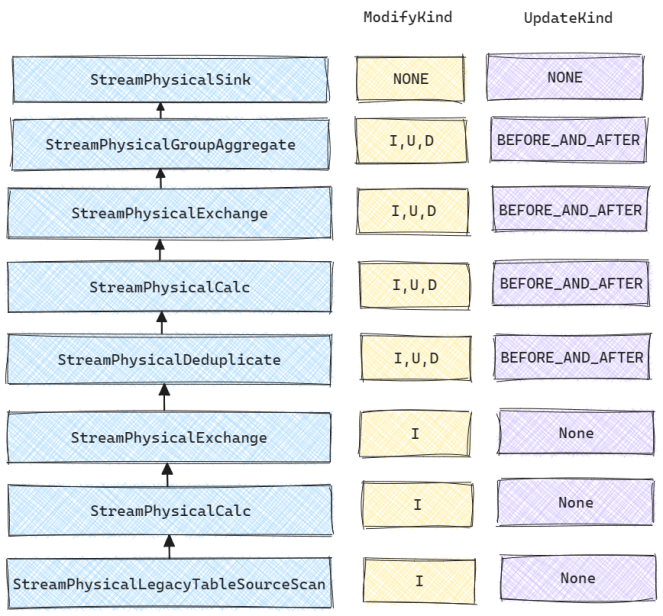
ModifyKindSetTrait推理流程
ModifyKindSetTrait推理的目标是确定每个算子的变更类型, 算子的变更类型受其输入算子的变更类型及其本身所执行的操作所影响, 例如对于StreamPhysicalGroupAggregate算子而言:
- 如果其输入算子只产生INSERT, 那么该算子只会产生INSERT和UPDATE;
- 如果其输入算子产生除了产生INSERT, 还会产生UPDATE或DELETE, 那么该算子就会同时产生INSERT, UPDATE和DELETE.
在推理过程中, 父节点会向子节点Require变更类型, 如果子节点的变更类型不满足父节点Require的输入变更类型, 就会抛出异常. 当子节点变更类型为父节点Require输入变更类型的子集时即为满足, 例如:
- 子节点变更类型
[I,U]满足父节点Require输入变更类型[I,U,D]; - 子节点变更类型
[I,U,D]不满足父节点Require输入变更类型[I,U].
ModifyKindSetTrait的推理过程在SatisfyModifyKindSetTraitVisitor.visit()中实现, 其本质上就是对算子树进行深度优先遍历. 这里先介绍一下两个重要的辅助函数:
visitChildren()函数包含两个参数,parent: StreamPhysicalRel和requiredChildrenTrait: ModifyKindSetTrait, 其功能就是对parent的所有子节点进行深度优先遍历, 其子节点的ModifyKindSetTrait必须满足requiredChildrenTrait, 否则就会抛出异常.createNewNode()函数包含五个参数,node: StreamPhysicalRel,children: List[StreamPhysicalRel],providedTrait: ModifyKindSetTrait,requiredTrait: ModifyKindSetTrait和requestedOwner: String. 其功能是更改node的ModifyKindSetTrait为providedTrait, 不过在创建新节点的过程中会检查providedTrait是否满足requiredTrait, 若不满足则会抛出异常. 其中,providedTrait是当前节点会产生的变更类型, 而requiredTrait是父节点Require的变更类型.
下面我们从下往上具体介绍一下上文案例中所涉及的各个算子的变更类型推导流程.
StreamPhysicalLegacyTableSourceScan的推导比较简单, 它本身只会产生INSERT, 因此直接调用createNewNode添加ModifyKindSetTrait.INSERT_ONLY即可.
1 | case _: StreamPhysicalDataStreamScan | _: StreamPhysicalLegacyTableSourceScan | |
StreamPhysicalCalc和StreamPhysicalExchange等一众算子本身并不会改变输入的变更类型, 因此只需要将子节点的变更类型进行穿透即可.
1 | case _: StreamPhysicalCalcBase | _: StreamPhysicalCorrelateBase | |
StreamPhysicalDeduplicate仅支持INSERT输入, 因此首先通过visitChildren()向子节点Require ModifyKindSetTrait.INSERT_ONLY. StreamPhysicalDeduplicate在保持处理时间下的第一条记录时仅会产生INSERT, 否则会产生所有变更类型.
1 | case deduplicate: StreamPhysicalDeduplicate => |
StreamPhysicalGroupAggregate可接受所有变更类型的输入, 如果输入包含UPDATE和DELETE那么可能产生DELETE, 否则不会产生DELETE.
1 | case agg: StreamPhysicalGroupAggregate => |
StreamPhysicalSink的处理流程相对特殊, 它首先通过deriveQueryDefaultChangelogMode()推导出附带的查询语句可能产生的变更类型, 然后通过对应的DynamicTableSink.getChangelogMode()来获取Sink节点可接受的变更类型, 最后会通过visitChildren()再次验证子节点的变更类型能否满足Sink节点的输入要求.
1 | case sink: StreamPhysicalSink => |
关于StreamPhysicalSink的上述处理流程, 这里在补充说明一下. Sink节点能够接受的变更类型是由对应输出目标决定的, 如果目标存储只能支持INSERT, 这时候其getChangelogMode()的实现如下, 此时如果对应的SELECT语句会输出UPDATE和DELETE(例如使用了GROUP BY), Table Planner在优化阶段就会直接抛出异常.
1 | public ChangelogMode getChangelogMode(ChangelogMode requestedMode) { |
UpdateKindTrait推理流程
UpdateKindTrait推理的目标是确定算子的更新类型, 需要注意的是变更类型和更新类型之间的区别, 更新类型是变更类型中UPDATE的两种具体形式, 即UPDATE_BEFORE和UPDATE_AFTER.
UpdateKindTrait的推理过程在SatisfyUpdateKindTraitVisitor.visit()中实现, 其本质上也是对算子树进行深度优先遍历. 这里同样先介绍一下两个辅助函数:
visitChildren()函数包含两个参数,parent: StreamPhysicalRel和requiredChildrenTrait: UpdateKindTrait, 其功能就是对parent的所有子节点进行深度优先遍历, 如果子节点的UpdateKindTrait不满足requiredChildrenTrait就会返回NONE, 否则返回UpdateKindTrait属性满足要求的相应节点.createNewNode()函数包含三个参数,node: StreamPhysicalRel,childrenOption: Option[List[StreamPhysicalRel]],providedTrait: UpdateKindTrait. 其功能是在node的UpdateKindTrait中添加providedTrait, 不过在创建新节点的过程中会检查providedTrait是否符合要求. 判断条件如下: 当providedTrait为UpdateKind.NONE时,node的ModifyKindSetTrait不能包含ModifyKind.UPDATE, 否则必须包含ModifyKind.UPDATE. 在不满足这一条件时便会抛出异常.
下面同样从下往上具体介绍一下上文案例中所涉及的各个算子的更新类型推导流程.
StreamPhysicalLegacyTableSourceScan仅会产生INSERT, 因此providedTrait直接传入UpdateKindTrait.NONE即可.
1 | case _: StreamPhysicalDataStreamScan | _: StreamPhysicalLegacyTableSourceScan | |
StreamPhysicalCalc仅在父节点需要UpdateKindTrait.ONLY_UPDATE_AFTER且存在过滤条件时返回None. 其他条件下直接将requiredTrait穿透给子节点即可.
1 | case calc: StreamPhysicalCalcBase => |
StreamPhysicalExchange直接将requiredTrait穿透给子节点即可.
1 | case _: StreamPhysicalCorrelateBase | _: StreamPhysicalLookupJoin | |
StreamPhysicalDeduplicate不需要向子节点Require任何更新类型, 因为它只支持INSERT类型的变更.
1 | case _: StreamPhysicalWindowAggregate | _: StreamPhysicalWindowRank | |
StreamPhysicalGroupAggregate当输入包含UPDATE变更时需要UPDATE_BEFORE, beforeAfterOrNone()在输入包含UPDATE时返回UpdateKind.BEFORE_AND_AFTER否则返回UpdateKind.NONE.
1 | case _: StreamPhysicalGroupAggregate | _: StreamPhysicalGroupTableAggregate | |
StreamPhysicalSink由于涉及到与外部系统的交互, 相对复杂. inferSinkRequiredTraits()会推导出Sink所需的更新类型, 例如当Sink节点仅支持UPDATE_AFTER时, 如果Upert Key是结果表Primary Key的子集, 那么Sink的子节点可以只产生UPDATE_AFTER从而提升性能. analyzeUpsertMaterializeStrategy用于确定是否需要添加SinkUpsertMaterializer, 后文会进一步讲述.
1 | case sink: StreamPhysicalSink => |
Sink算子Upsert物化
通过上面的分析可以看到, 在推导StreamPhysicalSink算子的UpdateKindTrait属性时, 需要分析是否需要添加SinkUpsertMaterializer算子, 这主要是为了解决分布式环境下Changelog乱序导致的结果不准确问题. 我们还是通过一个例子来具体地说明SinkUpsertMaterializer算子的作用.
示例的SQL如下, 读者可运行ChangelogJoinExample进行调试.
1 | CREATE TABLE source1 ( |
我们假设s2中已有两条记录+I(10,a1)和+I(20,b1). 此时s1下发了三条Changelog记录, 分别是+I(1,10), -U(1,10)和+U(1,20). 同时我们假设在运行时Join算子存在两个Task, 那么整个计算图如下图所示.
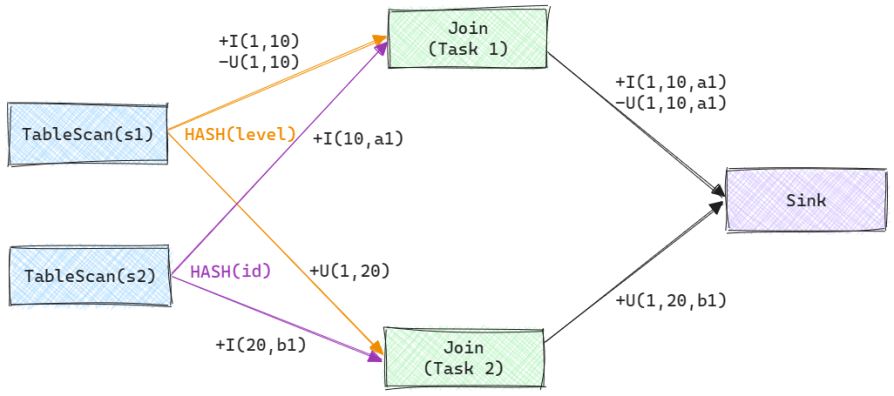
很明显在不存在乱序的情况下, 最终结果表中的记录应该是(1,20,b1). 但是由于有两个Join Task, 最终到达Sink算子的Changelog顺序可能存在以下3中情况. 注意由于+I(1,10,a1), -U(1,10,a1)来自同一个算子, 因此这两条记录之间一定会保持顺序. 可以看到, 后两种情况下乱序会导致结果表中不存在id=1的记录.

在介绍上述问题的解决方案之前, 我们先来分析一下出现这类问题的根本原因. 在SQL中有两个关于键的重要概念:
- Unique Key表示一个或多个能唯一标识一行数据的列.
- 如果某些Unique Key的顺序能够得到保证, 那么这些键称为Upsert Key.
对于Sink算子而言, 如果输入存在Upsert Key, 那么由于它是天然有序的, 直接按接受顺序更新到外部表即可. 在上述Join示例中, Sink算子的Unique Key是s1.id, 但是由于Join Key是s1.level, 所以同一个s1.id可能来自不同的Join算子, 这就导致s1.id的顺序无法保证, 因此也就不存在Upsert Key. 这种情况下如果不存在额外的操作, 就可能导致最终结果错误. 而对于文中开头的案例, 如果最终Sink表的Unique Key是tms_company, 那么由于Group by的Key也是tms_company, 因此同一个tms_company只可能来自于同一个Group算子, 这就意味着tms_company就是Upsert key, Sink算子只需直接写外部表即可, 不需要额外操作.
对于没有Upsert Key或者Upsert Key与Sink的Unique Key不同的情况, 为了保证乱序情况下结果的准确性, 必须要有额外的操作. Flink SQL会在Sink算子之前添加一个SinkUpsertMaterializer算子, 上述示例经过该算子之后的输出结果如下所示. 它会在状态中维护某个Upsert Key(如果没有Upsert Key就是整行记录)的更新历史, 这样在收到乱序的记录后就可以对其进行纠正, 具体的实现逻辑可参考SinkUpsertMaterializer.
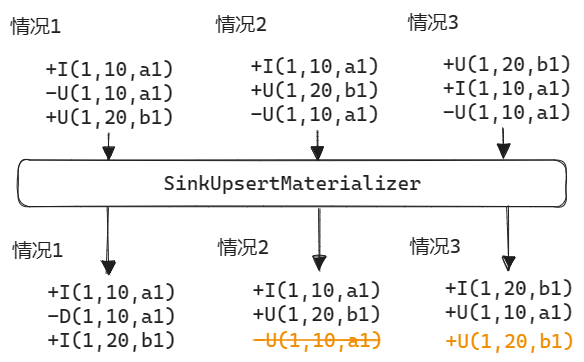
Transform图生成阶段
在关系代数优化阶段, Table Planner已经推导出了各个算子的ModifyKindSetTrait和UpdateKindTrait属性. 根据这些属性, 在Transform图生成阶段, 即可进行相应的代码生成和处理优化. 对于不同的算子, 需要有不同的逻辑来生成Changelog事件. 本文以Group聚合算子为例进行介绍, 在不开启Mini-Batch时其与Changelog相关的实现逻辑在GroupAggFunction中(算子调用链可参考笔者之前的博文), 处理流程如下图所示. 这里作几点简要说明:
GroupAggFunction实际上就是KeyedProcessFunction的继承类, 通过State管理历史聚合结果来实现Changelog的生成. 也就是说, 我们完全可以在DataStream API中借助KeyedProcessFunction来实现同样的效果, Flink SQL只不过是对整个过程进行了标准化.- 关系代数优化阶段推导出的
ModifyKindSetTrait和UpdateKindTrait可以帮助算子在实现时进行相应的优化, 例如如果StreamPhysicalGroupAggregate的下游算子不支持接受UPDATE_BEFORE, 那么GroupAggFunction完全可以不发送这一事件来减少数据传输和下游的处理压力, 在GroupAggFunction中是否需要发送Retraction记录是由generateUpdateBefore变量决定的, 仅当StreamPhysicalGroupAggregate的UpdateKindTrait为BEFORE_AND_AFTER时它的值为true.
总结
本文介绍了Flink SQL内部的Changelog机制, 它的形成也不是一蹴而就的, 而是在实践中不断演化, 才有了目前较为完善的Changelog实现. 即便如此, 在实践中还是可能存在问题, 例如多个流的Regular Join会导致Retraction放大, 降低执行效率. 在流计算场景中, 要在高效解决此类问题的同时保证语义的正确, 获取还需要额外的存储组件支持, 例如Apache Paimon的Partial Update. 本文围绕示例中的算子, 介绍了Changelog属性的推导流程, 虽然没有涉及全部算子, 不过在理解整个Changelog机制原理的基础上, 相信可以轻松理解其他算子的推导流程. 最后以Group算子为例介绍了Changelog语义的算子实现.
参考
[1] Retraction for Flink Streaming
[2] FLIP-95: New TableSource and TableSink interfaces
[3] FLIP-105: Support to Interpret Changelog in Flink SQL (Introducing Debezium and Canal Format)
[4] Flink SQL Secrets: Mastering the Art of Changelog Event Out-of-Orderness
[5] Flink Table的三种Sink模式
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送