本文已收录在合集数据系统经典论文阅读中.
本文是对Databricks的Delta Lake论文(Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores)的阅读总结. Delta Lake是前文所说的Lakehouse架构中的数据湖上的表格存储实现. 论文详细描述了Delta Lake的产生背景, 原理以及特征. 阅读论文不仅可以了解Delta Lake的实现原理, 还有助于了解其他表格存储实现, 如Apache Iceberg和Apache Hudi.
本文不会对论文进行完整的翻译, 而是按如下主线剖析论文的核心观点和内容, 并穿插笔者的见解:
- Delta Lake的产生背景.
- 对象存储的特性和挑战.
- Delta Lake的存储格式和访问协议.
Delta Lake的产生背景
云对象存储(Cloud Object Stores), 比如Amazon S3, Azure Blob Storage和阿里云OSS等, 具有极高的可靠性, 海量的存储空间以及低廉的价格. 除了云服务的传统优点, 云对象存储更重要的特性是支持存储与计算分离. 由于这些优点, 云对象存储很适合用来作为数据仓库(Data Warehouse)和数据湖(Data Lake)的存储底座. 目前开源的大数据系统, 如Spark, Hive, Presto, 以及商业服务, 如AWS Athena, Google BigQuery, Redshift Spectrum, 都支持使用Apache Parquet和ORC文件格式读写云对象存储.
不幸的是, 尽管许多系统支持对云对象存储的读写, 但借助这些系统和云对象存储并不能实现高效和可变的表格存储, 也就导致了难以在它们之上实现数据仓库功能. 这是因为与HDFS等分布式文件系统或DBMS中的自定义存储引擎不同, 大多数云对象存储仅仅是键值存储, 没有跨键一致性保证. 另外它们的性能特征也与分布式文件系统有很大不同. 目前在云对象存储中存储关系数据集最常见的方法是使用列式文件格式, 如Parquet和ORC, 其中每个表作为一组对象(Parquet或ORC文件)存储, 可能按某些字段聚集成分区(例如, 每个日期的单独一组对象). 只要目标文件比较大, 这种方法可以为扫描工作负载提供可接受的性能. 但是, 在如下几种复杂的场景中就不行了:
- 由于云对象存储中多对象更新不是原子的, 所以多个查询之间没有隔离: 例如, 如果一个查询需要更新表中的多个对象(例如, 删除表中所有Parquet文件中关于一个用户的记录), 其他查询将看到部分更新, 因为查询单独更新每个对象. 回滚写操作也很困难:如果更新查询崩溃, 表就处于部分更新的不一致状态.
- 对于拥有数百万个对象的大表, 元数据操作的开销很大. 例如, Parquet文件包括带有最小/最大统计信息的页脚, 可用于在选择性查询中跳过读取它们. 在HDFS上读取这样的页脚可能需要几毫秒, 但云对象存储的延迟要高得多, 这些数据跳过检查可能比实际查询花费更长的时间.
总结来说, 用云对象存储作为存储底座来实现数据仓库有两个重要的问题, 一是不支持事务, 二是小文件导致的性能问题. Delta Lake核心其实就是在云对象存储上引入了一个新的中间层, 来解决上述问题.
为了解决上述问题, Databricks设计了Delta Lake(2017年开始供客户使用, 2019年开源), 它是云对象存储之上具有ACID特性的表格存储层. 其核心思想十分简单: 使用本身存储在云对象存储中的预写日志, 以ACID的方式维护关于哪些对象是Delta表的一部分的信息. 也就是说Delta Lake除了原表之外, 还新增了一种预写日志(称为Transaction Log), 并以ACID的方式来维护, 这样就可以支持事务. 关于Transaction Log的具体内容, 下文会详细分析. 有了事务特性之后, Delta Lake还可以支持许多传统数据湖无法支持的特性, 比如:
- 时间旅行(Time travel)
- UPSERT, DELETE和MERGE操作(UPSERT, DELETE and MERGE operations)
- 高效的流式I/O(Effificient streaming I/O)
- 缓存(Caching): 因为Delta表及其日志中的对象是不可变的, 所以计算集群节点可以安全地将它们缓存在本地存储中. Databricks云服务中利用它来为Delta表实现一个透明的SSD缓存.
- 数据分布优化(Data layout optimization): 可以自动优化表中对象的大小和数据记录的聚集性(例如, 使用Z-order存储记录, 以实现多个维度的局部性), 而不会影响运行的查询.
- Schema演化(Schema evolution)
- 审计日志(Audit logging)
上述特性提高了数据湖的可管理性和性能, 使Lakehouse架构成为了现实. 更重要的是Delta Lake还能进一步简化整体的数据平台架构, 在存储上实现流批一体. 下图是一个案例, 图(a)中为了实现流式分析, BI和数据科学应用, 采用了消息队列, 数据湖和数据仓库系统三种组件, 引入Delta Lake之后可以仅使用这一组件来实现上述所有应用.
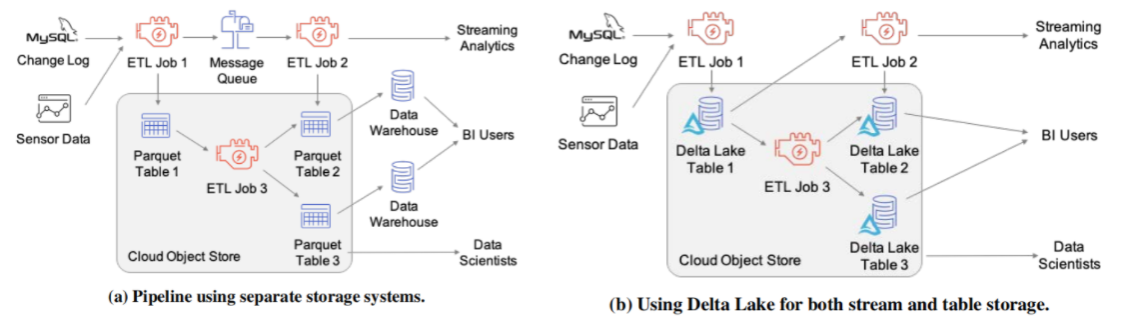
Delta Lake的特性使其可以在一定程度上实现流批一体, 论文中也说到了在流处理中其延迟是秒级的, 如果需要更低延迟的流处理, 可能还是得借助消息总线. 不过笔者相信流批一体是未来的一种趋势, 随着技术的进步未来更多的系统将会更好地兼顾流处理和批处理. 目前来说, 在存储方面有两种实现流批一体的思路, 其一是使用文件类型的存储来实现流批一体, 即类似Delta Lake这样数据湖上的表格存储; 另一种是使用消息队列来实现流批一体, 即类似Pulsar这样的消息队列. 除了存储之外, 还有计算的流批一体, 这里不再展开. 关于流批一体更详细的内容可参考浅谈大数据的过去, 现在和未来.
对象存储的特性
之所以在对象存储之上实现高效的表格存储比较困难, 是因为对象存储的几个特性.
对象存储的API
- 云对象存储都提供一个简单易扩展的键值存储API. 用户可以创建Bucket来存储多个Object, 每个Object都是一个二进制的Blob, 其大小最大一般限制在几个TB. 对象存储的键可以对应文件系统的路径, 但是与文件系统不同的是云对象存储更改键名(即文件路径)的代价较高.
- 云对象存储也提供了元数据API, 比如S3的
LIST操作可以根据给定的起始键, 按字典顺序列出Bucket中的Object. 不幸的是这些API大多比较昂贵, 比如S3的LIST操作每次仅返回1000个对象, 需要耗时几百毫秒, 如果表的文件数量较多就非常低效了. - 在读取Object时, 云对象存储支持按字节寻址, 并且支持高效的顺序读. 这使得利用特定存储格式(如Z-order)来聚集经常访问的值成为可能.
- 在更新Object时, 需要一次性重写整个Object. 这些更新是具有原子性, 用户要么读到更新前的版本, 要么读到更新后的版本. 有些系统也支持追加写操作.
一致性特性
- 当前流行的云对象存储为每个键提供最终一致性, 但不能保证跨键一致性, 这给管理由多个对象组成的数据集带来了挑战. 比如, 在客户端上传一个新对象之后, 其他客户端不一定能在
LIST中看到该对象或立即进行读取操作. 同样, 对现有对象的更新可能不会立即对其他客户端可见. 此外, 根据对象存储的不同, 即使是进行写操作的客户端自身也可能不会立即看到新对象. - 云对象存储确切的一致性模型因云提供商而异, 可能相当复杂. 举一个具体的例子, Amazon S3为写入新对象的客户端提供了写后读的一致性, 这意味着读取操作(如S3的
GET)将在PUT之后返回对象内容. 但是有一个例外:如果写入对象的客户端在其PUT之前向(不存在的)键发出GET, 那么后续的GET可能在一段时间内不会读取对象, 这很可能是因为S3使用了负缓存. 另外, S3的LIST操作总是最终一致性的, 这也意味着PUT之后的LIST未必会返回新对象.
性能特性
- 每个读操作通常会产生至少5-10毫秒的基本延迟, 然后可以以大约50-100MB/s的速度读取数据, 因此一个操作需要至少读取几百KB才能达到顺序读的峰值吞吐量的一半, 并需要多个MB才能接近峰值吞吐量. 此外, 在典型的VM配置中, 应用程序需要并行运行多个读取, 以最大化吞吐量. 例如, 在AWS上最常用于分析的VM类型至少有10Gbps的网络带宽, 因此它们需要并行运行8-10次读取以充分利用这一带宽.
- S3的
LIST操作每个请求最多只能返回1000个对象, 并且需要数十到数百毫秒的时间, 因此客户端需要并行发出数百个LIST来列出大的Bucket下的所有对象. 在DeltaLake中, 关于可用对象的元数据(包括它们的名称和数据统计信息)存储在Delta日志中(为了避免使用LIST). - 写操作通常必须替换整个对象(或追加). 这意味着, 如果一个表希望进行点更新, 那么表中的对象应该保持较小, 这与支持大型读取相悖. 另一种方法是使用日志结构的存储格式.
云对象存储的上述性能特性, 对分析性作业有以下指导原则:
- 将频繁访问的数据按顺序存放在一起, 比如采用列式存储或Z-order排列.
- 使用大对象, 但不要太大. 大对象增加了更新数据的成本(例如, 删除一个用户的所有数据), 因为它们必须完全重写.
- 避免
LIST操作, 尽可能让这些操作请求按字典顺序排列的键区间.
现有表格存储方法
基于对象存储的这些特性, 目前有三种主要的方法在对象存储上管理表数据.
- 文件目录(Directories of Files): 开源大数据技术栈和许多云服务支持的最常见的方法是将表存储为对象的集合, 通常采用列式存储(如Parquet). 这些对象可进一步按日期或其他字段进行分区. 这种方法源自Hive在HDFS上管理关系型数据. 但是这种方法在云对象存储中有性能和事务问题:
- 没有跨多个对象的原子性: 任何需要写入或更新多个对象的事务都有部分写入对其他客户端可见的风险. 此外, 如果这样的事务失败, 数据将处于损坏状态.
- 最终一致性: 即使事务成功了, 客户端也可能看部分更新.
- 性能差: 列出对象以查找与查询相关的对象的开销很大, 即使它们按键分区到目录中. 此外, 访问存储在Parquet或ORC文件中的每个对象的统计数据非常昂贵, 因为它需要对每个特性进行额外的高延迟读取.
- 没有管理功能: 对象存储没有实现数据仓库中常见的标准实用程序, 如表版本控制或审计日志.
- 自定义存储引擎(Custom Storage Engines):比如Snowflake的数据仓库系统通过在一个独立的, 强一致性的服务中管理元数据本身, 可以绕过云对象存储的许多一致性挑战, 该服务拥有关于哪些对象组成一个表的”source of truth”. 在这些引擎中, 云对象存储可以被视为一个简单的块设备. 这类引擎也面临以下一些挑战:
- 对一个表的所有I/O操作都需要访问元数据服务, 这可能会增加其资源成本, 降低性能和可用性.
- 与重用现有开放格式(如Parquet)的方法相比, 计算引擎的连接器需要更多的工程工作来实现.
- 专有元数据服务将用户绑定到特定的服务提供商, 而基于直接访问云存储中的对象的方法使用户始终可以使用不同的技术访问其数据.
- 在对象存储中维护元数据(Metadata in Object Stores):DeltaLake的方法是在云对象存储中直接存储事务日志和元数据, 并使用一组特定协议来实现可序列化. Apache Hudi和Apache Iceberg都采用了相同的方式.
Delta Lake的存储格式和访问协议
DeltaLake表是云对象存储或文件系统上的一个目录, 它保存包含表内容的数据对象和事务操作日志(偶尔有检查点). 客户端使用针对云对象存储特性定制的乐观并发控制协议更新这些数据结构.
存储格式
Delta表的存储格式如下图所示.
- 表的内容以Parquet文件进行存储, 可以像Hive那样进行分区. 例如下图中的表按
date字段进行了分区, 同一天的数据在同一文件夹下. Delta表中的数据对象都有一个唯一的名称(GUID), 哪个对象属于表的哪个版本由事务日志决定. _delta_log文件夹下存储的是事务日志. 它包含一些列按序增长的JSON文件, 以及Checkpoint文件. 每个日志记录对象(例如000003.json)包含一个操作数组, 用于应用于表的上一个版本, 以生成下一个版本. 可用的操作有:metaData:metaData操作更改表的当前元数据. 表的第一个版本必须包含一个metaData操作.add和remove:add用于向Delta表中添加对象, 也可以包含数据的统计值, 如每列的最大最小值以及null值的数量等.remove用于删除对象, 它包含一个时间戳用于指示删除发生的时间. 物理的删除是惰性的, 可由用户指定删除延迟.protocol:protocol操作用于增加表的版本(在读或写时需要). 该操作还可以用于添加新的特性.commitInfo:commitInfo操作中包含来源信息, 用于指示哪个用户执行了操作.- Update Application Transaction IDs: Delta Lake允许用户写入自定义的
txn操作, 包含appId和version. 这一特性可用于在流计算中实现Exactly-Once语义, 比如将源的Offset作为version写入, 这样就能在流计算作业崩溃时进行恢复.
- 为了提升性能, Delta Lake会合并日志文件, 比如下图中的
000003.parquet是前三个日志文件合并的结果._last_checkpoint中记录了最新的Checkpoint ID. 这样客户端在读取时就不需要用LIST列举日志文件, 只需读取最新的Checkpoint文件即可.

访问协议
Delta Lake的访问协议旨在让客户端只使用对象存储上的操作来实现可序列化的事务, 尽管对象存储只保证最终一致性. 使之成为可能的关键选择是使用日志作为根数据结构, 例如000003.json, 客户机需要知道它才能读取表的特定版本. 有了日志的内容, 客户端就可以从对象存储中查询其他对象, 如果它们由于最终一致性还不可见, 则可能会等待, 然后读取表数据. 对于执行写操作的事务, 客户端需要一种方法来确保只有一个写入者可以创建下一个日志记录, 然后可以使用这种方法来实现乐观并发控制.
只读事务
Delta Lake的只读事务支持客户端安全地读取表的某一个版本, 其执行步骤如下:
- 读取表的日志目录中的
_last_checkpoint对象(如果存在的话), 以获得最近的检查点ID. - 使用
LIST操作以最后一个检查点ID(如果存在, 否则为0)为开始键, 在表的日志目录中查找任何更新的.json和.parquet文件. 这提供了一个列表文件, 可用于从最近的检查点开始重建表的状态. (注意, 由于云对象存储的最终一致性, 这个LIST操作可能返回一个不连续的对象集, 例如000004. json和000006.json, 而不包含000005.json. 尽管如此, 客户机可以使用返回的最大ID作为目标表版本进行读取, 并等待丢失的对象变得可见.) - 使用检查点(如果存在)和上一步中标识的后续日志记录来重构表的状态——即有
add记录但没有相应remove记录的数据对象集, 以及它们相关的数据统计信息. Delta Lake的设计使得这个任务可以并行运行: 例如, 在Spark连接器中, 使用Spark作业读取检查点Parquet文件和日志对象. - 使用统计信息来识别与查询相关的数据对象文件集.
- 查询对象存储以读取相关的数据对象, 可能在整个集群中并行读取. 注意, 由于云对象存储的最终一致性, 一些工作节点可能无法查询查询规划器在日志中找到的对象; 这些可以在短时间内重试.
Delta Lake的只读事务可以在只支持最终一致性的对象存储上实现快照隔离. 如果由于最终一致性, 导致当前客户端读取到的最大日志ID不是最新的, 这种情况可以视为读取了表在某个时刻的快照.
写事务
Delta Lake写事务的执行步骤如下:
- 使用只读事务的步骤1-2标识一个最近的日志记录ID, 例如$r$(即从最后一个检查点ID向前查找). 然后事务将读取表版本$r$(如果需要)的数据, 并尝试写入日志记录$r+1$.
- 在表版本$r$上读取数据, 如果需要, 使用与读取协议相同的步骤(即合并之前的检查点和任何进一步的日志记录, 然后读取这些记录中引用的数据对象).
- 将事务想要增加到表中的任何新数据写入新的对象存储文件中, 使用GUID生成对象名称. 这个步骤可以并行进行. 最后, 可以在新的日志记录中引用这些对象.
- 如果没有其他客户端写入该对象, 则尝试将事务的日志记录写入
r+1.json. 这个步骤需要是原子的. 如果步骤失败, 可以重试事务; 根据查询的语义, 客户机还可以重用它在步骤3中写入的新数据对象, 并简单地尝试将它们添加到新的日志记录中的表中. - 也可以为日志记录$r+1$编写一个新的
.parquet检查点(默认每10条记录执行一次). 然后, 在这个写入完成之后, 更新_last_checkpoint文件, 使其指向检查点$r+1$.
在第4步中, 创建日志的操作需要是原子的. 在不同存储中有不同的实现方法:
- Google Cloud Storage和Azure Blob Store支持原子的
put-if-absent操作, 可以直接使用它. - 在像HDFS这样的分布式文件系统上, 使用原子rename将一个临时文件重命名为目标名称(例如
000004.json), 或者如果它已经存在则失败. Azure Data Lake Storage还提供了一个带有原子重命名的文件系统API, 因此这里也可使用相同的方法. - Amazon S3不支持原子的
put-if-absent操作以及重命名操作. 在Databricks的服务中, 新增了一个Coordinate服务来保证只有一个客户端可以创建特性ID的日志. 在Delta Lake开源的Spark Connector中, 保证通过同一个Spark Context的写入会获得不同的日志ID. 不过也提供了LogStoreAPI用于实现自定义的服务.
总结
Delta Lake在数据湖上实现了表格存储, 用于支撑Lakehouse架构. 从实现上来看, Delta Lake并没有使用什么复杂的新技术, 只是将数据库系统中的日志引入进来, 却产生了意想不到的效果. 由此可见, 大数据系统中的很多创新就是将传统数据库系统中的技术重新应用到现有的分布式架构中.
参考
[1] Databricks Delta Lake 论文阅读笔记
[2] Understanding the Delta Lake Transaction Log [译文]
本博客所有文章除特别声明外, 均采用CC BY-NC-SA 3.0 CN许可协议. 转载请注明出处!
关注笔者微信公众号获得最新文章推送